
Anthropic shipped two flagships in the same family: Claude Sonnet 4.5 for hard reasoning and Claude Haiku 4.5 for fast, cheap calls. Same API surface, same prompt format, three-times-different pricing. Pick wrong and your bill quietly triples for tasks Haiku could finish in half a second.
This guide is the cheat sheet I wish I'd had when I rewrote our routing layer last month. We'll walk through the real trade-offs, the cost math, and a drop-in router you can paste into any service that talks to EzAI.
Quick comparison
Both models support the same 200K context window, the same tool-calling format, vision, and JSON mode. The differences live in latency, raw reasoning, and price.
- Haiku 4.5 — ~2-3× faster end-to-end, $1 / $5 per million tokens (input/output), great at extraction, classification, summarisation, simple agent steps.
- Sonnet 4.5 — top-tier coding and multi-step planning, $3 / $15 per million tokens, the model you reach for when an answer being wrong is expensive.
If your workload is "rewrite this email", "label this ticket", "extract these fields" — Haiku wins, full stop. If it's "refactor this 800-line file" or "plan a deploy", Sonnet earns the markup.
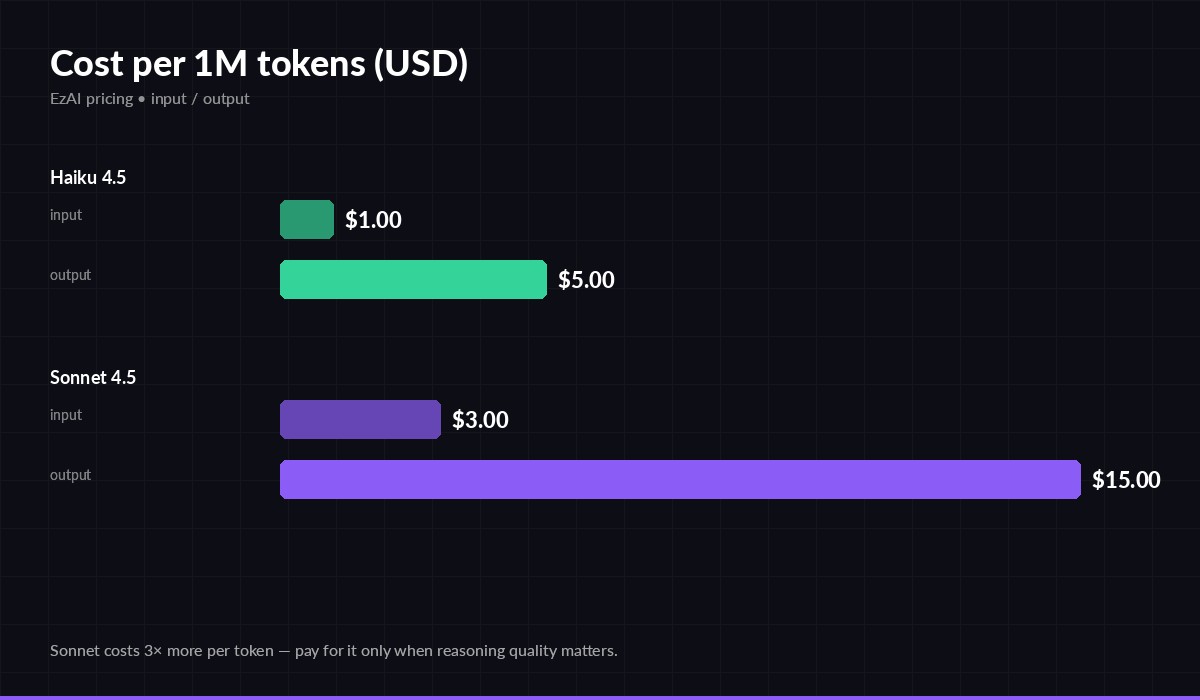
Same family, 3× the price — Sonnet's premium is real, so spend it on purpose
Cost per million tokens
The price gap matters most on output tokens, where Sonnet costs $15 versus Haiku's $5. A chatbot answering 10K user messages a day at ~400 output tokens each burns:
- Haiku: 10K × 400 × $5 / 1M = $20/day
- Sonnet: 10K × 400 × $15 / 1M = $60/day
That's $1,200/month you save by routing intelligently — without your users noticing, because most of those 10K messages don't need Sonnet's brain. The trick is knowing which ones do.
Where Haiku is enough
Send these to Haiku 4.5 and stop overthinking it:
- Classification & routing — "Is this ticket billing, technical, or sales?" Haiku hits this with near-perfect accuracy and sub-second latency.
- Extraction — Pulling structured fields out of invoices, emails, or scraped HTML. Pair with JSON mode and you're done.
- Summarisation of short docs — Anything under ~5K tokens summarises beautifully on Haiku.
- Conversational replies — FAQ bots, onboarding flows, retrieval-augmented chat where the LLM is a polite stitcher of context, not a thinker.
- Streaming UX — Haiku's first-token latency makes typing-style UIs feel instant.
Quick test in Python — same SDK, just swap the model string:
import anthropic, json
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
resp = client.messages.create(
model="claude-haiku-4-5",
max_tokens=256,
system="Classify the ticket. Reply with one of: billing, technical, sales.",
messages=[{"role": "user", "content": "My card was charged twice for the same invoice."}],
)
print(resp.content[0].text) # billingWhere Sonnet earns its keep
Reach for Sonnet 4.5 when the cost of a wrong answer is bigger than 3× the token bill:
- Coding agents — Multi-file edits, refactors, debugging. Sonnet plans, Haiku ad-libs.
- Long-context reasoning — Anything past ~30K tokens of input where you need real understanding, not pattern-matching.
- Tool-using agents with branching logic — Sonnet keeps state across 10+ tool calls without losing the thread.
- Anything safety-critical — Legal review, medical triage scaffolding, financial summaries.
If you're using extended thinking, Sonnet is the only one of the two that supports it well — Haiku has the feature but the reasoning depth isn't comparable.
Build a smart router (cheap by default, smart on demand)
The cleanest pattern I've shipped: classify the request with Haiku, then route to either Haiku or Sonnet. Your bill drops, your p95 latency drops, and only the hard 10–20% of traffic pays Sonnet pricing.
import anthropic
client = anthropic.Anthropic(api_key="sk-your-key", base_url="https://ezaiapi.com")
ROUTER_PROMPT = """You are a router. Reply with ONLY one word:
'haiku' for: short Q&A, classification, extraction, simple summaries, <5K tokens.
'sonnet' for: code refactors, multi-step plans, long-context analysis, tool-heavy agents."""
def pick_model(user_msg: str) -> str:
r = client.messages.create(
model="claude-haiku-4-5",
max_tokens=5,
system=ROUTER_PROMPT,
messages=[{"role": "user", "content": user_msg[:2000]}],
)
pick = r.content[0].text.strip().lower()
return "claude-sonnet-4-5" if "sonnet" in pick else "claude-haiku-4-5"
def answer(user_msg: str) -> str:
model = pick_model(user_msg)
r = client.messages.create(
model=model,
max_tokens=2048,
messages=[{"role": "user", "content": user_msg}],
)
return r.content[0].textThe router call costs roughly $0.000005 per request — invisible. In production we see ~75% of traffic resolved by Haiku and ~25% escalated to Sonnet, which works out to a ~60% reduction in spend versus "always Sonnet". For deeper patterns, see our writeup on model routing strategies and multi-model fallback.
Latency: don't ignore the felt difference
Money matters, but so does perceived speed. On a typical 800-token completion through EzAI, Haiku 4.5 lands first-token in roughly half the time of Sonnet, and finishes in roughly a third. For chat UIs, that's the difference between "snappy" and "thinking…". Stream both with SSE and the gap is even more obvious — see the SSE streaming guide for a working setup.
A simple decision rule
When in doubt, walk this checklist top-to-bottom and stop at the first yes:
- Does the task involve writing or refactoring more than ~50 lines of code? → Sonnet
- Does it need to plan multiple steps or call several tools in sequence? → Sonnet
- Is the input over ~30K tokens and you need actual comprehension? → Sonnet
- Is being wrong here expensive (legal, financial, medical)? → Sonnet
- Otherwise → Haiku
Run that rule for a week and you'll know your real Sonnet ratio. For most products it's well under 30%.
Wrapping up
Sonnet 4.5 and Haiku 4.5 aren't competing — they're a tier system. Use Haiku for the boring 80%, save Sonnet for the work that earns its premium, and let a tiny router decide. With EzAI you swap models by changing one string and watch the savings on the dashboard in real time. Anthropic publishes the official model spec on the Anthropic docs site if you want to dig deeper.
Already routing? Next read: 7 ways to reduce AI API costs and prompt caching — both stack on top of model routing for another ~30-50% savings.