If you're choosing between Claude Opus vs GPT-5 in 2026, you're asking the right question — but you're missing a third contender. Anthropic's Claude Opus 4.6, OpenAI's GPT-5.2, and Google's Gemini 3.1 Pro are the three flagship AI models that define the current generation. Each dominates different workloads, and picking the wrong one costs you real money and productivity.
We've tested all three extensively through EzAI API's unified endpoint, analyzed published benchmarks, and compiled real-world developer feedback. Here's the no-BS breakdown of where each model excels, where it falls short, and which one you should actually use.

Claude Opus 4.6 — The Coding and Reasoning King
Claude Opus 4.6 from Anthropic is the best model available today for software engineering and autonomous agent workflows. That's not an opinion — it's what the benchmarks say.
Where it dominates:
- Terminal-Bench 2.0: 65.4% — industry-leading for agentic terminal coding
- SWE-Bench Verified: 80.8% — highest single-attempt score among all models
- OSWorld: 72.7% — best computer-use model on the market
- Extended thinking: Hybrid reasoning that scales from instant responses to deep multi-step problem solving
- Context window: 200K standard, up to 1M in beta
Where it falls short:
- Most expensive of the three — $5/M input, $25/M output at official pricing
- Slower than GPT-5.2 for simple queries (extended thinking adds latency)
- No native image generation or video understanding
Pricing via EzAI: $5.00/M input tokens, $25.00/M output tokens. Cache reads drop to $0.50/M — a massive saving if you're making repeated calls with shared context.
GPT-5.2 — The Professional Knowledge Worker
GPT-5.2 from OpenAI is the best model for general knowledge work, multimodal tasks, and business-oriented outputs. It's OpenAI's most capable model ever, and it shows in professional benchmarks.
Where it dominates:
- GDPval: 70.9% — outperforms human industry professionals at knowledge work tasks across 44 occupations
- GPQA Diamond: 92.4% — near-perfect on expert-level science questions
- AIME 2025: 100% — perfect score on competition math (no tools)
- ARC-AGI-1: 86.2% — strong abstract reasoning
- Speed: Fastest of the three for standard responses
- Multimodal: Excellent vision, spreadsheet generation, and presentation creation
Where it falls short:
- Terminal-Bench 2.0: 54.0% — noticeably behind Opus 4.6 (65.4%) and Gemini 3.1 Pro (68.5%) in agentic coding
- Context window limited to 128K — smallest of the three
- Weaker at long-running autonomous agent tasks compared to Claude
Pricing via EzAI: $2.50/M input tokens, $10.00/M output tokens. The best value per dollar of the three flagships. GPT-5.2-codex is available at the same price for code-focused workloads.
Gemini 3.1 Pro — The Benchmark Sweeper
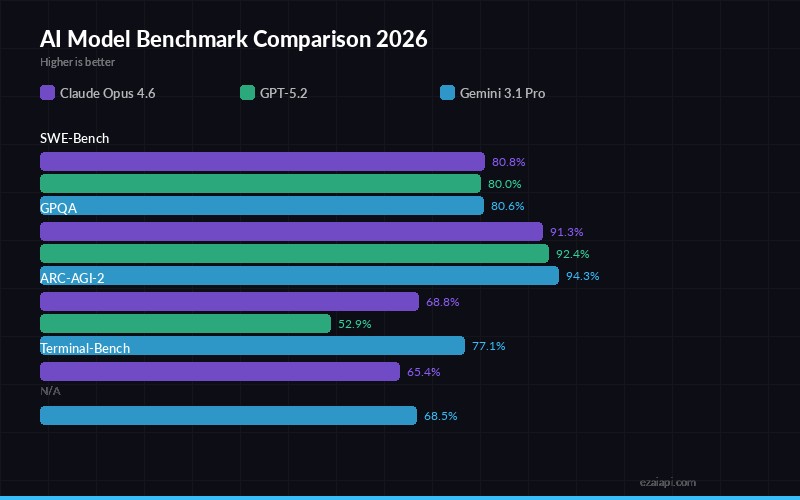
Benchmark scores — SWE-Bench, GPQA, ARC-AGI-2, and Terminal-Bench across major models
Gemini 3.1 Pro from Google DeepMind has quietly become the most well-rounded model in the market. Its benchmark results are staggering — it leads or ties in more categories than any other model.
Where it dominates:
- Terminal-Bench 2.0: 68.5% — highest of any model (with Thinking High)
- ARC-AGI-2: 77.1% — demolishes the competition (Opus 4.6: 68.8%, GPT-5.2: 52.9%)
- Humanity's Last Exam: 44.4% (no tools) — best academic reasoning score
- GPQA Diamond: 94.3% — edges out GPT-5.2's 92.4%
- BrowseComp: 85.9% — best agentic search by a wide margin
- Context window: 1M tokens standard, with native video and audio input
- True multimodal: Text, image, video, audio, and PDF input — the most versatile input support
Where it falls short:
- Still in Preview — expect occasional instability
- SWE-Bench Pro: 54.2% with single attempt — competitive but not dominant
- Ecosystem maturity lags behind OpenAI and Anthropic (tooling, SDK support)
Pricing via EzAI: $1.25/M input tokens, $10.00/M output tokens. The cheapest input pricing of any flagship model — 4x cheaper than Opus on input, 2x cheaper than GPT-5.2.
Head-to-Head: AI Model Benchmark Comparison
Here's how the three models compare across key benchmarks. All scores use Thinking mode enabled. Winners are highlighted in green.
| Benchmark | Opus 4.6 | GPT-5.2 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-Bench Verified | 80.8% | 80.0% | 80.6% |
| Terminal-Bench 2.0 | 65.4% | 54.0% | 68.5% |
| ARC-AGI-2 | 68.8% | 52.9% | 77.1% |
| GPQA Diamond | 91.3% | 92.4% | 94.3% |
| Humanity's Last Exam | 40.0% | 34.5% | 44.4% |
| BrowseComp | 84.0% | 65.8% | 85.9% |
| OSWorld | 72.7% | — | — |
| GDPval (Knowledge Work) | — | 70.9% | — |
| Context Window | 200K (1M beta) | 128K | 1M |
| Input Price (per 1M) | $5.00 | $2.50 | $1.25 |
| Output Price (per 1M) | $25.00 | $10.00 | $10.00 |
Sources: Anthropic, OpenAI, Google DeepMind. Scores are self-reported by each company as of Feb 2026.
When to Use Which Model — Practical Recommendations
Stop agonizing. Here are opinionated recommendations based on real usage patterns:
Pick Claude Opus 4.6 when:
- You're writing production code — Opus is the most reliable code generator. It plans before it writes, catches its own mistakes, and handles large codebases with confidence. For Claude Code workflows, nothing else comes close.
- You need autonomous agents — Complex multi-step task chains where the model runs for minutes without human intervention. Opus handles longer chains with fewer errors.
- Extended thinking matters — For problems that need deep reasoning (architecture decisions, complex debugging, mathematical proofs), Opus's extended thinking mode is unmatched.
Pick GPT-5.2 when:
- You need speed — GPT-5.2 returns responses faster than both competitors for standard queries. For latency-sensitive applications, it wins.
- Professional knowledge work — Presentations, spreadsheets, financial models, document analysis. GPT-5.2 was literally designed for this — it outperforms human professionals on GDPval.
- Budget-conscious coding — At $2.50/M input, GPT-5.2-codex gives you 80% of Opus's coding quality at half the price. For most everyday coding tasks, that's the smart choice.
Pick Gemini 3.1 Pro when:
- You're processing long documents — 1M token context window is 5–8x larger than the competition. For analyzing entire codebases, legal contracts, or research papers, Gemini is the only viable option.
- Multimodal input matters — Video analysis, audio transcription, PDF parsing — Gemini handles input types the others can't touch.
- You want the best benchmarks per dollar — At $1.25/M input, Gemini 3.1 Pro's benchmark-topping performance is absurdly cost-effective. It leads in more benchmark categories than either competitor at a fraction of the price.
How to Access All Three Through One API
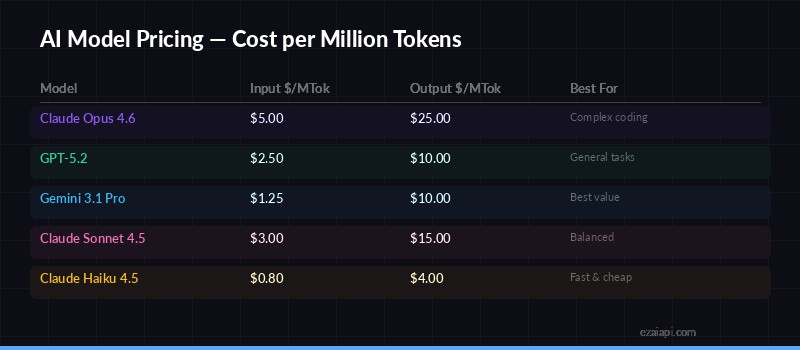
Token pricing via EzAI — input and output costs per million tokens
The real power move? Don't choose just one. Use EzAI API to access Claude Opus 4.6, GPT-5.2, and Gemini 3.1 Pro through a single endpoint with one API key. Switch between models by changing a single parameter — no separate accounts, no multiple billing dashboards.
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-ezai-key",
base_url="https://ezaiapi.com"
)
# Use Claude Opus for complex coding
opus = client.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
messages=[{"role": "user", "content": "Refactor this module..."}]
)
# Use GPT-5.2 for fast analysis
gpt = client.messages.create(
model="gpt-5.2",
max_tokens=2048,
messages=[{"role": "user", "content": "Analyze this report..."}]
)
# Use Gemini for long context
gemini = client.messages.create(
model="gemini-3.1-pro-preview",
max_tokens=8192,
messages=[{"role": "user", "content": "Summarize this 500K document..."}]
)All three calls use the same SDK, the same API format, and the same billing. Check our docs for the full list of 20+ supported models, or see pricing for per-model costs.
Extended Thinking for Complex Tasks
Both Claude Opus 4.6 and Gemini 3.1 Pro support extended thinking — where the model spends extra time reasoning through complex problems before responding. For architecture decisions, hard debugging sessions, or multi-step analysis, extended thinking dramatically improves output quality. GPT-5.2 offers a similar "Thinking" mode with configurable effort levels.
Through EzAI, you can enable extended thinking on any supported model with the same API parameters. No configuration changes needed — just pass the thinking parameter and the model does the rest.
The Verdict: Best AI Model 2026
There is no single "best AI model" — but there is a best model for your specific use case:
- Best for coding: Claude Opus 4.6. The SWE-Bench and OSWorld results speak for themselves. If code quality is your top priority, pay the premium.
- Best for speed + value: GPT-5.2. Half the price of Opus, fastest response times, and strong-enough coding for 80% of tasks.
- Best all-rounder: Gemini 3.1 Pro. Tops the most benchmarks, cheapest input pricing, 1M context window. If you could only pick one model, this is the one.
But the smartest developers aren't picking one — they're using all three through a unified API like EzAI, routing each task to the model that handles it best. One key, one endpoint, every model. That's how you win in 2026.