
Your production AI app is humming along. Thousands of requests per hour, customers happy. Then Anthropic's API returns 529 for 20 minutes during peak traffic. Your entire service goes down. Users churn. Revenue lost.
This isn't hypothetical — every major AI provider has had outages in the past year. The fix isn't hoping it won't happen again. It's multi-model fallback: automatically routing to a backup model when your primary goes down. With EzAI API, you can set this up in under 50 lines of Python.
Why Single-Provider Architectures Break
Most teams start with one AI provider. It's simpler — one SDK, one billing dashboard, one set of prompts to tune. But single-provider architectures have three fatal problems:
- Outages are inevitable. Anthropic, OpenAI, and Google have all had multi-hour outages. When your only provider goes down, so does your product.
- Rate limits hit at the worst time. Traffic spikes during product launches, marketing campaigns, or viral moments — exactly when you need capacity most.
- Pricing changes without warning. A provider doubles their price overnight? If you're locked in, you eat the cost or scramble to migrate.
Multi-model fallback solves all three. Your primary model handles normal traffic. When it fails, your app automatically switches to a backup — no user-facing errors, no pager alerts at 3 AM.
The Fallback Pattern with EzAI
Because EzAI gives you access to Claude, GPT, and Gemini through one endpoint, implementing fallback is trivial. You don't need three separate API keys or SDKs. Just change the model parameter.
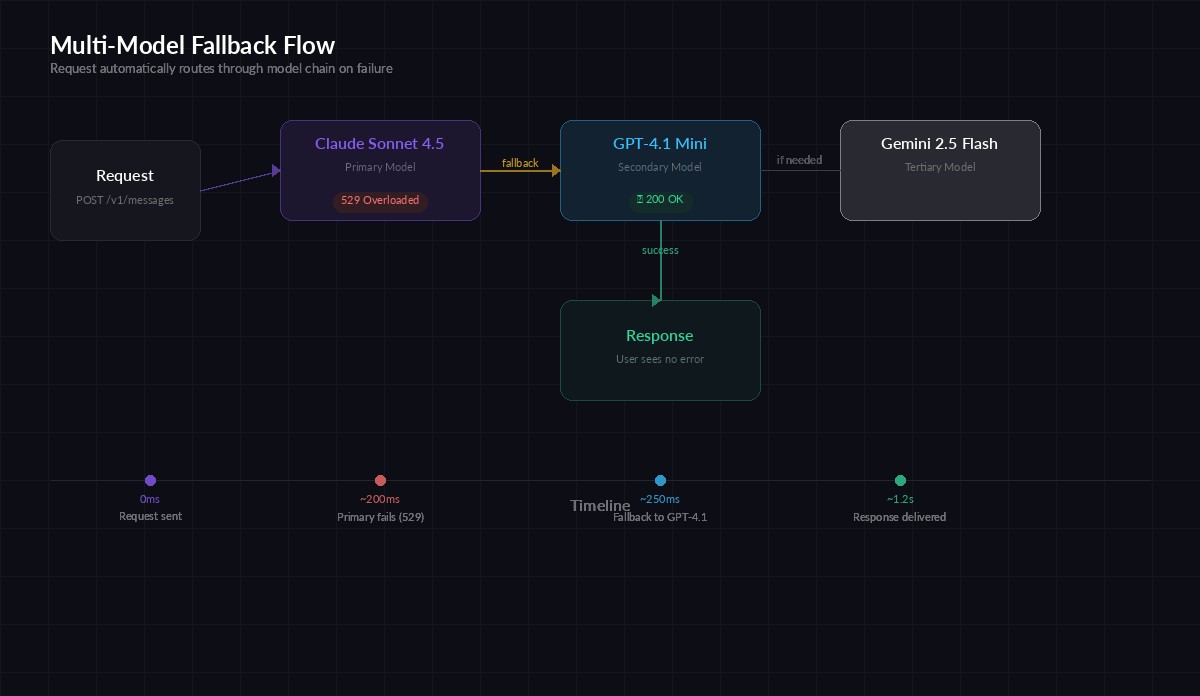
Request flows through primary → secondary → tertiary model with automatic failover
Here's a production-ready fallback client in Python:
import anthropic
import time
import logging
# Define your model chain: primary → fallbacks
MODEL_CHAIN = [
"claude-sonnet-4-5", # Primary: best quality
"gpt-4.1-mini", # Secondary: fast + cheap
"gemini-3-flash-preview", # Tertiary: different provider
]
RETRIABLE_ERRORS = (429, 500, 502, 503, 529)
client = anthropic.Anthropic(
api_key="sk-your-ezai-key",
base_url="https://ezaiapi.com",
)
def call_with_fallback(messages, max_tokens=1024):
for i, model in enumerate(MODEL_CHAIN):
try:
response = client.messages.create(
model=model,
max_tokens=max_tokens,
messages=messages,
)
if i > 0:
logging.info(f"Fallback succeeded with {model}")
return response
except anthropic.APIStatusError as e:
if e.status_code in RETRIABLE_ERRORS:
logging.warning(
f"{model} returned {e.status_code}, "
f"trying next model..."
)
continue
raise # 400, 401 etc. are real errors
raise RuntimeError("All models in chain failed")That's the core pattern. Try the primary model. If it returns a retriable error (rate limit, server error, overloaded), move to the next model in the chain. If all fail, raise an error for your application to handle.
Adding Retry Logic with Exponential Backoff
Sometimes a model fails briefly then recovers. Adding a single retry per model before moving to fallback catches transient blips without slowing down real outages:
import random
def call_with_retry_and_fallback(
messages,
max_tokens=1024,
retries_per_model=1,
base_delay=0.5,
):
for model in MODEL_CHAIN:
for attempt in range(retries_per_model + 1):
try:
return client.messages.create(
model=model,
max_tokens=max_tokens,
messages=messages,
)
except anthropic.APIStatusError as e:
if e.status_code not in RETRIABLE_ERRORS:
raise
if attempt < retries_per_model:
delay = base_delay * (2 ** attempt)
jitter = random.uniform(0, delay * 0.1)
time.sleep(delay + jitter)
else:
logging.warning(
f"{model} failed after {retries_per_model + 1} "
f"attempts, falling back..."
)
raise RuntimeError("All models exhausted")The jitter prevents thundering herd problems — if 1,000 requests all retry at the exact same moment, you've just made the rate limit worse. Adding random jitter spreads retries across time.
Streaming Fallback for Real-Time Apps
If you're streaming responses to users, fallback needs to work at the stream level. You can't switch models mid-stream, but you can detect failure before any tokens arrive:
def stream_with_fallback(messages, max_tokens=1024):
for model in MODEL_CHAIN:
try:
with client.messages.stream(
model=model,
max_tokens=max_tokens,
messages=messages,
) as stream:
for text in stream.text_stream:
yield text
return # Success — exit the loop
except anthropic.APIStatusError as e:
if e.status_code not in RETRIABLE_ERRORS:
raise
logging.warning(f"Stream failed on {model}, trying next")
raise RuntimeError("All models failed to stream")The key insight: the stream() context manager connects to the API when you enter it. If the connection fails (rate limit, server error), the exception fires immediately — before any tokens are yielded. That means fallback is seamless to the consumer.
Choosing Your Model Chain
The order of your fallback chain matters. Here are three strategies depending on your priorities:
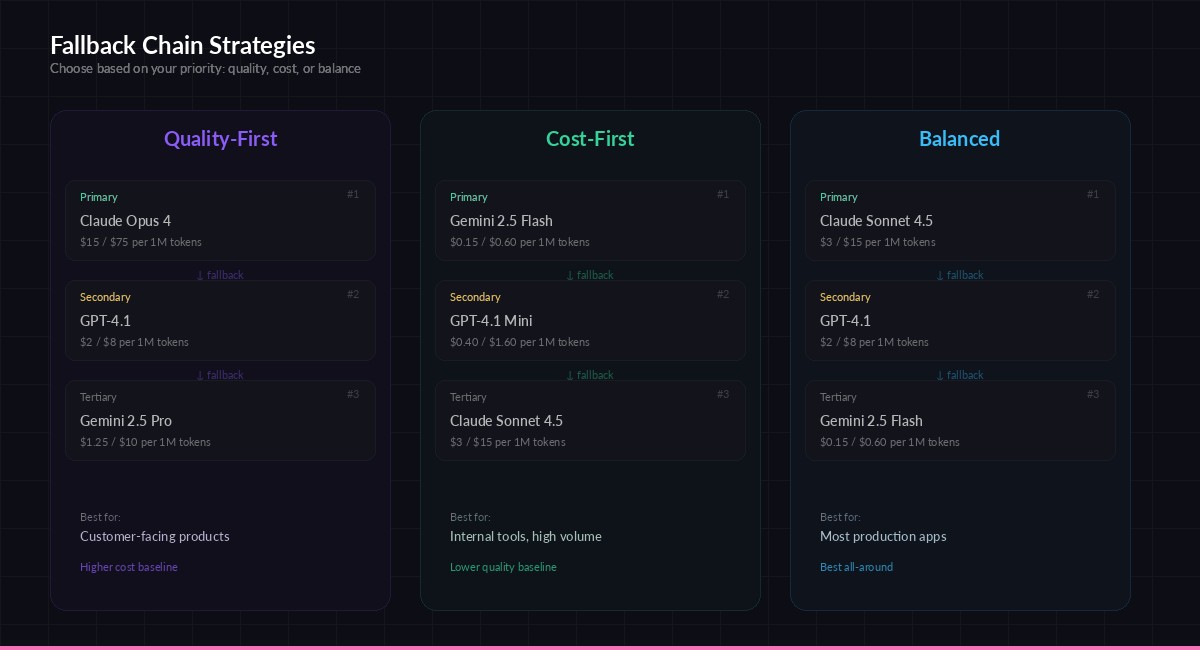
Pick a chain strategy based on whether you optimize for quality, cost, or balance
Quality-first — Use the best model as primary and fall back to slightly cheaper alternatives. Good for customer-facing products where response quality matters most.
# Quality-first: best model → good model → acceptable model
QUALITY_CHAIN = ["claude-opus-4", "gpt-4.1", "gemini-2.5-pro"]
# Cost-first: cheapest → medium → premium (only if needed)
COST_CHAIN = ["gemini-3-flash-preview", "gpt-4.1-mini", "claude-sonnet-4-5"]
# Balanced: mid-tier primary → diverse fallbacks
BALANCED_CHAIN = ["claude-sonnet-4-5", "gpt-4.1", "gemini-3-flash-preview"]The key is provider diversity. If all three models are from the same provider, a provider-wide outage takes out your entire chain. Mix Anthropic, OpenAI, and Google models so a single provider failure never takes you offline.
Monitoring and Alerting
Fallback should be invisible to users, but very visible to you. Log every fallback event so you know when your primary model is having issues:
from collections import defaultdict
# Track fallback frequency
fallback_counts = defaultdict(int)
def call_with_metrics(messages, max_tokens=1024):
for i, model in enumerate(MODEL_CHAIN):
try:
start = time.monotonic()
response = client.messages.create(
model=model,
max_tokens=max_tokens,
messages=messages,
)
latency = time.monotonic() - start
if i > 0:
fallback_counts[model] += 1
logging.warning(
f"FALLBACK: used {model} "
f"(total fallbacks: {fallback_counts[model]})"
)
logging.info(
f"model={model} latency={latency:.2f}s "
f"tokens={response.usage.output_tokens}"
)
return response
except anthropic.APIStatusError as e:
if e.status_code not in RETRIABLE_ERRORS:
raise
raise RuntimeError("All models failed")In production, you'd push these metrics to Prometheus, Datadog, or whatever observability stack you use. Set an alert when fallback rate exceeds 5% — that's a signal your primary model's provider is degraded.
Why EzAI Makes This Easy
Without a unified proxy like EzAI, multi-model fallback requires managing separate API keys for Anthropic, OpenAI, and Google. Separate billing, separate SDKs, separate auth. With EzAI:
- One API key — Access Claude, GPT, and Gemini through the same endpoint
- One SDK — The Anthropic Python SDK works for all models, just change the model name
- One bill — Track costs across all providers in one dashboard
- Lower costs — EzAI's pricing is often 50-80% below direct API costs
You can have a resilient, multi-provider AI architecture running in production in under an hour. No vendor agreements, no separate accounts, no billing headaches.
Quick Start
Ready to set this up? Here's the fastest path:
- Sign up for EzAI and grab your API key
- Copy the
call_with_fallbackfunction from above into your codebase - Replace your existing single-model call with
call_with_fallback(messages) - Add logging and monitor fallback rates
That's four steps to go from "one provider goes down, we go down" to "one provider goes down, nobody notices." Your users will never know the difference, but your SLA will thank you.