
Most developers pick one AI model — usually the latest Opus or GPT — and throw everything at it. Summarizing a changelog? Opus. Formatting JSON? Opus. Checking if a string is empty? Believe it or not, Opus. That's like driving a semi truck to buy groceries. It works, but you're burning fuel for nothing.
Model routing means matching each task to the cheapest model that can handle it. A well-routed system uses Haiku or GPT-4o Mini for simple stuff, Sonnet for everyday coding, and reserves Opus for the genuinely hard problems. The result: 40-70% lower costs with zero quality loss on the tasks that matter.
Why One Model Doesn't Fit All
AI models sit on a spectrum of capability and cost. Here's the rough pricing landscape through EzAI in early 2026:
- Claude Haiku 3.5 — $0.80/M input, $4/M output. Fast, cheap, solid at classification and extraction
- Claude Sonnet 4.5 — $3/M input, $15/M output. The sweet spot for code generation, analysis, writing
- Claude Opus 4.6 — $15/M input, $75/M output. Research-grade reasoning, complex multi-step tasks
- GPT-4o Mini — $0.15/M input, $0.60/M output. Great for formatting, simple Q&A, data extraction
That's a 100x price difference between GPT-4o Mini and Opus. If 60% of your requests are simple enough for a small model, you're leaving serious money on the table by routing everything to a flagship.
The Routing Decision Tree
Here's a practical framework for deciding which model handles what. No ML classifier needed — just a few conditionals in your code:
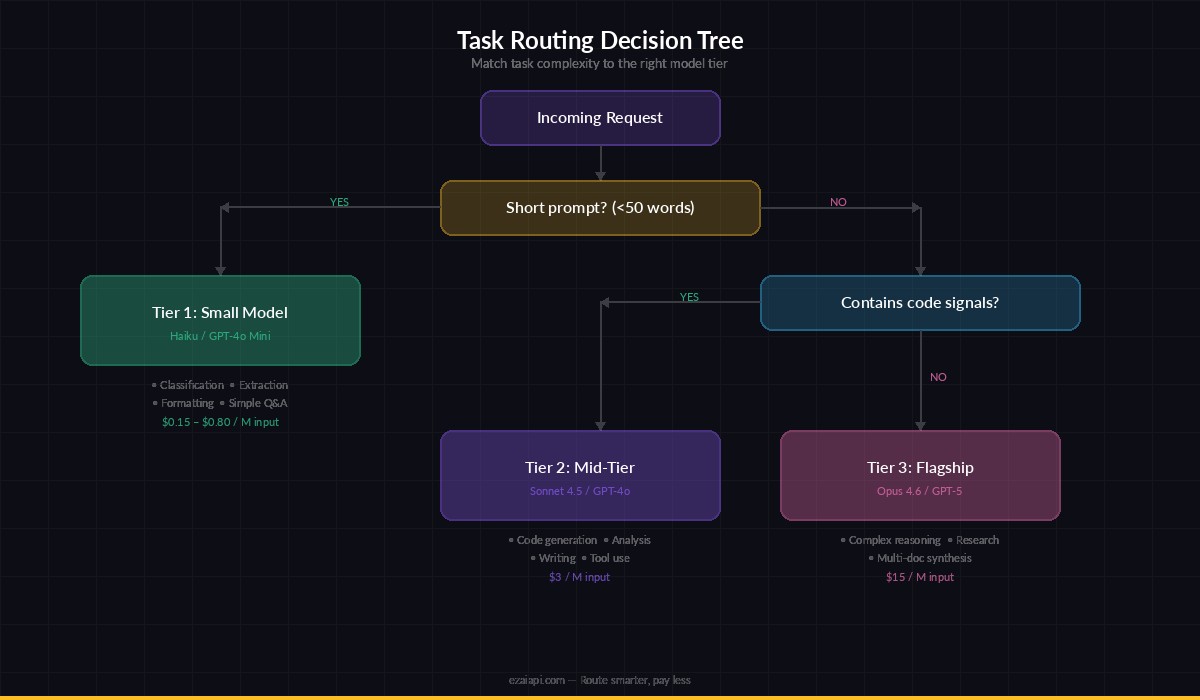
Route tasks by complexity — most requests don't need a flagship model
Tier 1: Small Models (Haiku, GPT-4o Mini)
- Text classification (sentiment, intent, category)
- Data extraction from structured text
- JSON formatting and schema validation
- Simple translation and summarization
- Yes/no decisions, boolean checks
Tier 2: Mid-Tier (Sonnet 4.5, GPT-4o)
- Code generation and debugging
- Long-form writing with specific tone
- Multi-step data analysis
- API integration and tool use
- Document comparison and summarization
Tier 3: Flagship (Opus 4.6, GPT-5)
- Novel architecture design
- Complex mathematical reasoning
- Multi-document synthesis with conflicting sources
- Tasks requiring extended thinking (budget >10k tokens)
Building a Router in Python
Here's a practical router class that picks the model based on task metadata. It works with EzAI's API — same endpoint, just swap the model name:
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com"
)
# Task complexity → model mapping
MODELS = {
"simple": "claude-3-5-haiku-latest",
"medium": "claude-sonnet-4-5",
"complex": "claude-opus-4-6",
}
def classify_task(prompt: str, max_tokens: int) -> str:
"""Cheap heuristic — no AI call needed."""
word_count = len(prompt.split())
# Short prompts with simple asks → small model
if word_count < 50 and max_tokens < 500:
return "simple"
# Code generation or analysis → mid-tier
code_signals = ["```", "function", "class ", "def ", "import "]
if any(s in prompt for s in code_signals):
return "medium"
# Long context or reasoning-heavy → flagship
if word_count > 2000 or max_tokens > 4000:
return "complex"
return "medium" # safe default
def routed_call(prompt, max_tokens=1024, force_model=None):
tier = classify_task(prompt, max_tokens)
model = force_model or MODELS[tier]
response = client.messages.create(
model=model,
max_tokens=max_tokens,
messages=[{"role": "user", "content": prompt}]
)
return response, model, tierThe classify_task function uses zero AI calls — pure heuristics. That's the point. You don't want to spend tokens figuring out which model to use. Word count, token budget, and keyword detection cover 90% of routing decisions.
Advanced: Fallback Chains
Sometimes a cheaper model fails — maybe the output is malformed JSON, or it misses a nuance. A fallback chain tries the cheap model first, then escalates if quality checks fail:
import json
FALLBACK_CHAIN = [
"claude-3-5-haiku-latest", # try cheap first
"claude-sonnet-4-5", # escalate
"claude-opus-4-6", # last resort
]
def extract_json_with_fallback(prompt):
for model in FALLBACK_CHAIN:
resp = client.messages.create(
model=model,
max_tokens=2048,
messages=[{"role": "user", "content": prompt}]
)
text = resp.content[0].text
try:
result = json.loads(text)
print(f"✅ Success with {model}")
return result
except json.JSONDecodeError:
print(f"⚠️ {model} returned invalid JSON, escalating...")
continue
raise ValueError("All models failed to produce valid JSON")In practice, Haiku handles JSON extraction correctly about 85% of the time. When it doesn't, Sonnet catches the remaining 14%. Opus almost never gets called — but it's there as a safety net. Your average cost per request drops dramatically because most calls resolve at the cheapest tier.
Real-World Routing Patterns
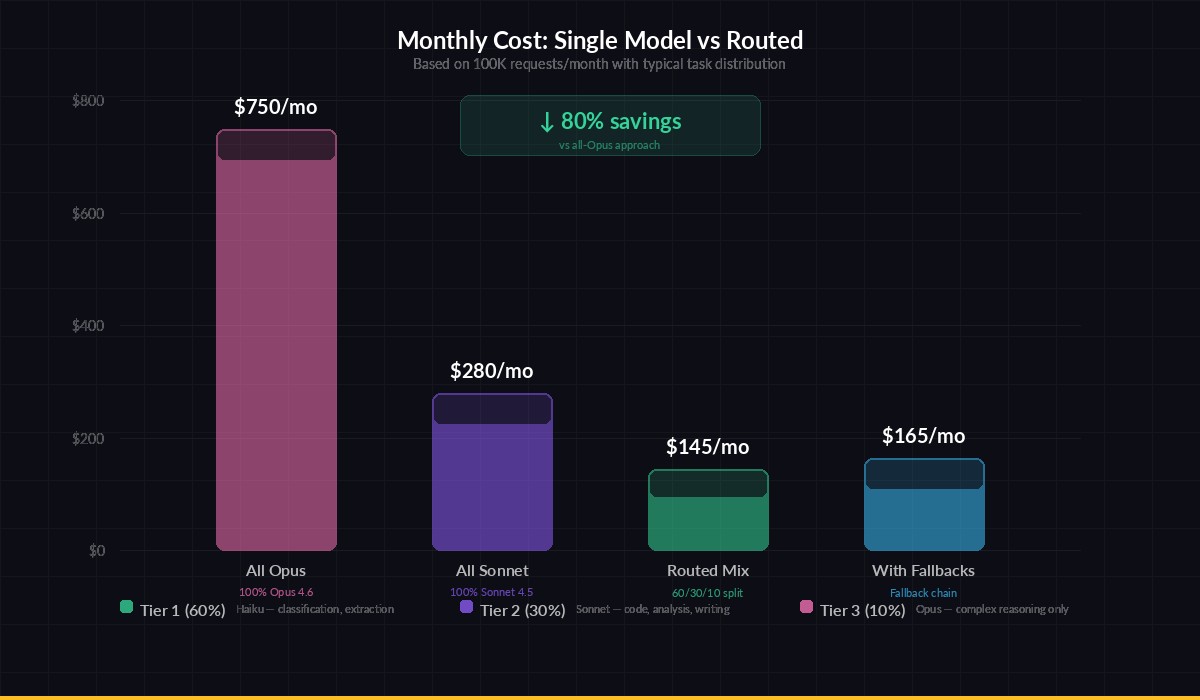
Routed approach saves 60%+ on typical production workloads
Here are three patterns we see teams using in production:
Pattern 1: The Triage Bot
A customer support system that classifies incoming tickets with Haiku (intent detection, priority scoring), drafts responses with Sonnet, and escalates edge cases to Opus with extended thinking enabled. Average cost per ticket: $0.003 instead of $0.04.
Pattern 2: The Code Pipeline
A CI/CD integration that uses Haiku for linting suggestions, Sonnet for code review comments, and Opus for architecture-level refactoring proposals. The pipeline runs on every PR but costs under $0.10 per run.
Pattern 3: The Content Engine
A content platform that generates outlines with Sonnet, writes drafts with Sonnet, fact-checks with Opus, and generates social snippets with Haiku. Total cost per article: ~$0.15 instead of $0.80 with Opus for everything.
Quick Wins You Can Ship Today
You don't need a complex routing system to start saving. Here are three changes you can make in ten minutes:
- Audit your model usage. Check your EzAI dashboard — look at which models handle which requests. If everything goes to one model, there's room to optimize.
- Downgrade your simplest calls. Find the classification, extraction, and formatting tasks in your codebase. Switch them to Haiku or GPT-4o Mini. Test that outputs are still correct.
- Add
force_modeloverrides. Keep a way to pin specific flows to specific models. When a new model drops, you can A/B test without changing routing logic.
# Before: everything goes to Opus
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=200,
messages=[{"role": "user",
"content": "Classify this email as spam or not: ..."}]
)
# After: use the right tool for the job
response = client.messages.create(
model="claude-3-5-haiku-latest", # 19x cheaper, same accuracy
max_tokens=200,
messages=[{"role": "user",
"content": "Classify this email as spam or not: ..."}]
)Monitoring Your Routing
Routing without monitoring is guessing. Track three metrics:
- Cost per tier — Are you actually saving? Compare monthly spend before and after routing.
- Escalation rate — How often does a cheap model fail and escalate? If it's over 20%, your heuristics need tuning.
- Quality scores — Spot-check outputs from each tier weekly. Small models degrade faster on edge cases.
EzAI's dashboard shows per-model breakdowns, making it easy to see exactly how much each tier costs you. Check your cost reduction guide for more optimization strategies.
Wrapping Up
Model routing isn't rocket science. It's the same principle engineers have used forever: use the smallest tool that gets the job done. A hash map lookup doesn't need a database query. A spam check doesn't need Opus.
Start simple — heuristic routing with a fallback chain. Measure the savings. Then iterate. Most teams see 40-70% cost reduction within the first week. With EzAI, you can switch models per-request without managing multiple API keys or endpoints. One gateway, all models, smart routing.
Get your API key and start routing today.