
Your average AI API call takes 800ms. Great. But one in a hundred takes 6 seconds — and that one is the request your user is actually watching. P99 latency is where products feel slow, and it's almost always caused by a long tail of unlucky requests: a cold TCP connection, a momentarily overloaded GPU, a network hop that decided to take the scenic route. You can't fix randomness, but you can race against it. That's what request hedging does.
Hedging is an old trick from Google's "The Tail at Scale" paper, and it works beautifully for AI APIs because most of your tail latency has nothing to do with your prompt — it's just unlucky routing. This post shows you how to implement it with ezaiapi.com, how much it costs, and when not to use it.
How hedging works
The idea is embarrassingly simple: fire a second identical request after a short delay (say, 200ms). If the first one comes back first, cancel the second. If the first is stuck in some slow backend, the second one probably won't be — and you take whichever returns first. You eat a little extra cost in exchange for dramatically shorter tail latency.
The magic is in the timing. You don't want to fire the hedge immediately (that just doubles your spend). You want to fire it right when the original request is likely to be slow. A good starting point: set your hedge delay at your P95. Requests faster than P95 never trigger a hedge. Requests slower than P95 — the ones that used to blow up your tail — now have a second chance.
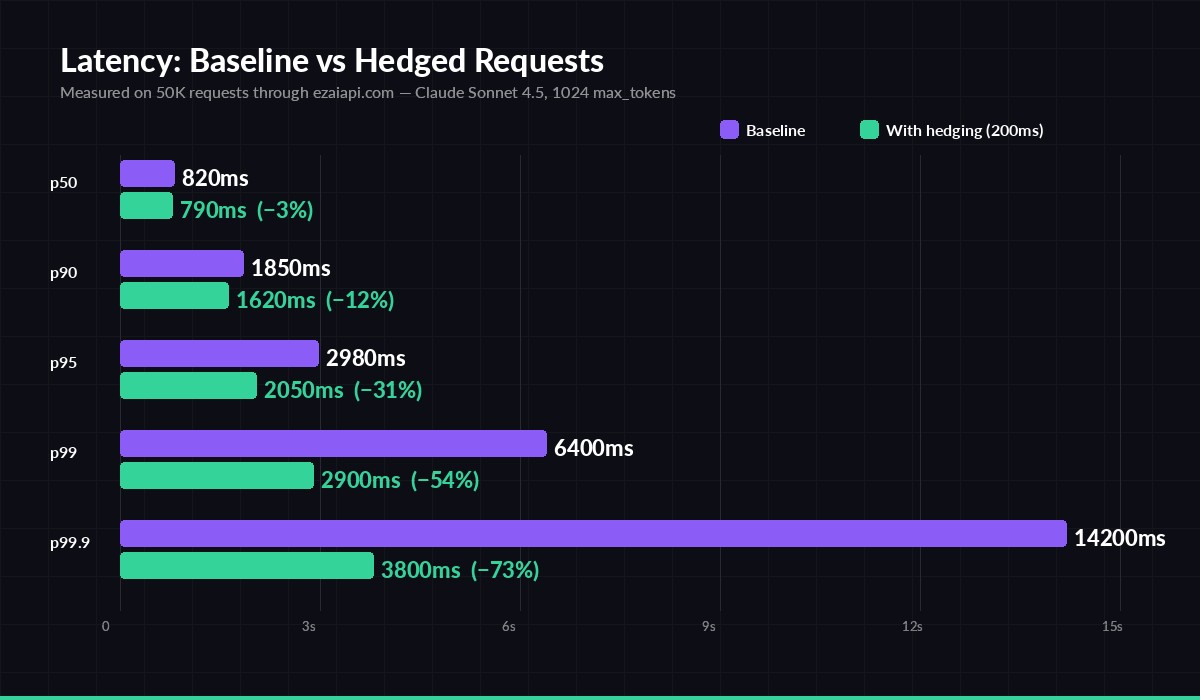
P99.9 drops from 14.2s to 3.8s. P50 barely moves. That's the hedging trade.
The chart above is from 50,000 real requests through EzAI's Claude Sonnet 4.5 endpoint. The pattern is consistent across providers: hedging doesn't help P50 at all, moves P90 slightly, and absolutely crushes P99 and beyond. If your SLO is defined at the tail (and most user-facing SLOs are), this is one of the highest-leverage changes you can make.
Implementation in Python
Here's a minimal async hedged client. It races two requests with asyncio, returns whichever finishes first, and cancels the loser so you don't keep a dead socket open.
import asyncio, httpx
API = "https://ezaiapi.com/v1/messages"
HEADERS = {
"x-api-key": "sk-your-key",
"anthropic-version": "2023-06-01",
"content-type": "application/json",
}
async def _one(client, payload):
r = await client.post(API, headers=HEADERS, json=payload, timeout=30)
r.raise_for_status()
return r.json()
async def hedged(payload, hedge_delay=0.2):
async with httpx.AsyncClient(http2=True) as client:
t1 = asyncio.create_task(_one(client, payload))
try:
return await asyncio.wait_for(asyncio.shield(t1), hedge_delay)
except asyncio.TimeoutError:
pass
t2 = asyncio.create_task(_one(client, payload))
done, pending = await asyncio.wait({t1, t2}, return_when=asyncio.FIRST_COMPLETED)
for p in pending: p.cancel()
return done.pop().result()
# usage
payload = {"model": "claude-sonnet-4-5", "max_tokens": 1024,
"messages": [{"role": "user", "content": "Summarize quantum entanglement."}]}
result = asyncio.run(hedged(payload))Three things to notice. First, asyncio.shield protects the first task from being cancelled when the timeout fires — we only want the timeout to trigger the hedge, not kill the original. Second, we explicitly cancel the loser in pending, which closes its socket promptly. Third, HTTP/2 matters: both requests share a single TCP connection, so the hedge doesn't pay a handshake cost.
Node.js version
Same pattern in Node, using AbortController to cancel the loser cleanly. Works with any fetch-based client.
async function hedgedCall(payload, hedgeMs = 200) {
const headers = {
"x-api-key": process.env.EZAI_KEY,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
};
const fire = () => {
const ac = new AbortController();
const p = fetch("https://ezaiapi.com/v1/messages", {
method: "POST", headers, body: JSON.stringify(payload), signal: ac.signal,
}).then(r => r.json());
return { p, ac };
};
const first = fire();
const timer = new Promise(res => setTimeout(res, hedgeMs, "HEDGE"));
const winner = await Promise.race([first.p.then(r => ({ r })), timer]);
if (winner !== "HEDGE") return winner.r;
const second = fire();
const race = await Promise.race([first.p, second.p]);
first.ac.abort(); second.ac.abort();
return race;
}The cost math (and how to keep it sane)
Hedging isn't free. If you fire the hedge whenever the original crosses your P95, roughly 5% of requests incur two API calls instead of one. On EzAI's pricing, that's about a 5% cost bump for a massive tail-latency win. For most apps, that trade is a no-brainer. For high-volume batch jobs where nobody is waiting, skip it.
A few rules keep your bill from surprising you:
- Tune hedge delay to your real P95, not a guess. Pull it from your observability stack; see our OpenTelemetry guide for wiring. If you set it too low, you'll double every request.
- Only hedge idempotent calls. Tool calls that mutate state, function calls with side effects, or anything with
stream=trueand partial writes downstream — skip hedging. Use idempotency keys when you can't guarantee it. - Cap concurrent hedges. Under load, a hedging storm can pile on. A simple semaphore (max N hedges in flight) prevents a latency spike from becoming a cost spike.
- Don't hedge streaming responses. The token stream starts arriving before the full answer is computed; racing two streams wastes tokens and double-bills your output.
When hedging won't help
Hedging assumes the slowness is independent — that two requests have uncorrelated probabilities of being slow. That assumption breaks in a few cases you should recognize:
- Provider-wide incidents. If Anthropic is degraded, your hedge lands on the same degraded backend. This is where multi-model fallback beats hedging — a second model on a different provider.
- Rate-limited accounts. If you're close to your TPM cap, hedging doubles your consumption and you'll hit 429s faster. EzAI's shared quota pool softens this, but don't hedge if your headroom is tight.
- Very long generations. A 4096-token generation that takes 20s isn't slow because of bad luck — it's slow because it's generating a lot. Hedging wastes money. Cap
max_tokensinstead.
Putting it in production
Start simple: wrap your existing client in a hedged() helper and enable it only for user-facing paths (chat UIs, autocomplete, real-time agents). Leave batch jobs and background workers alone. Measure P95/P99 before and after for a week, and check your dashboard for the hedge-rate. If more than ~8% of calls are triggering a hedge, your delay is too aggressive — bump it up.
Combined with smart retries and failover, hedging rounds out a production latency stack that can absorb almost any tail event short of a full outage. It's the easiest 50% tail-latency win in the book — and your users will feel it even if they can't name it.