
A user clicks "Generate" twice. Your retry logic fires after a timeout. A load balancer replays a request during failover. Each of these sends the same prompt to the AI API — and each one costs you tokens. Idempotency is how you stop paying for the same work twice. This guide walks through building an idempotency layer in Python with Redis that deduplicates AI API calls, returns cached responses for repeated requests, and handles race conditions cleanly.
Why AI APIs Need Idempotency
Traditional REST APIs are cheap per call. A duplicate GET /users costs microseconds. But AI API calls are expensive — a single Claude Opus request with 4K input tokens and 2K output can cost $0.15+. Multiply that by retry storms, double-clicks, or frontend re-renders, and you're burning real money on identical work.
The math is straightforward. If 5% of your requests are unintentional duplicates and you make 10,000 calls per day at an average cost of $0.03 each, that's $15/day — $450/month — wasted on responses you already had.
Unlike traditional caching, idempotency operates on request identity, not response freshness. Two requests with identical inputs within a time window should return the same response, regardless of cache headers or TTL policies.
The Idempotency Key Pattern
The core idea: generate a deterministic key from the request payload, check Redis before calling the API, and store the response after a successful call. Here's the building block:
import hashlib, json, redis, anthropic
r = redis.Redis(host="localhost", port=6379, db=0)
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com"
)
def make_idempotency_key(model, messages, max_tokens, system=None):
"""Deterministic key from request params."""
payload = {
"model": model,
"messages": messages,
"max_tokens": max_tokens,
"system": system or "",
}
raw = json.dumps(payload, sort_keys=True)
return f"idem:{hashlib.sha256(raw.encode()).hexdigest()[:16]}"The key is a SHA-256 hash of the serialized request body. We truncate to 16 hex characters (64 bits) — collision probability stays negligible for typical workloads, and shorter keys mean faster Redis lookups.
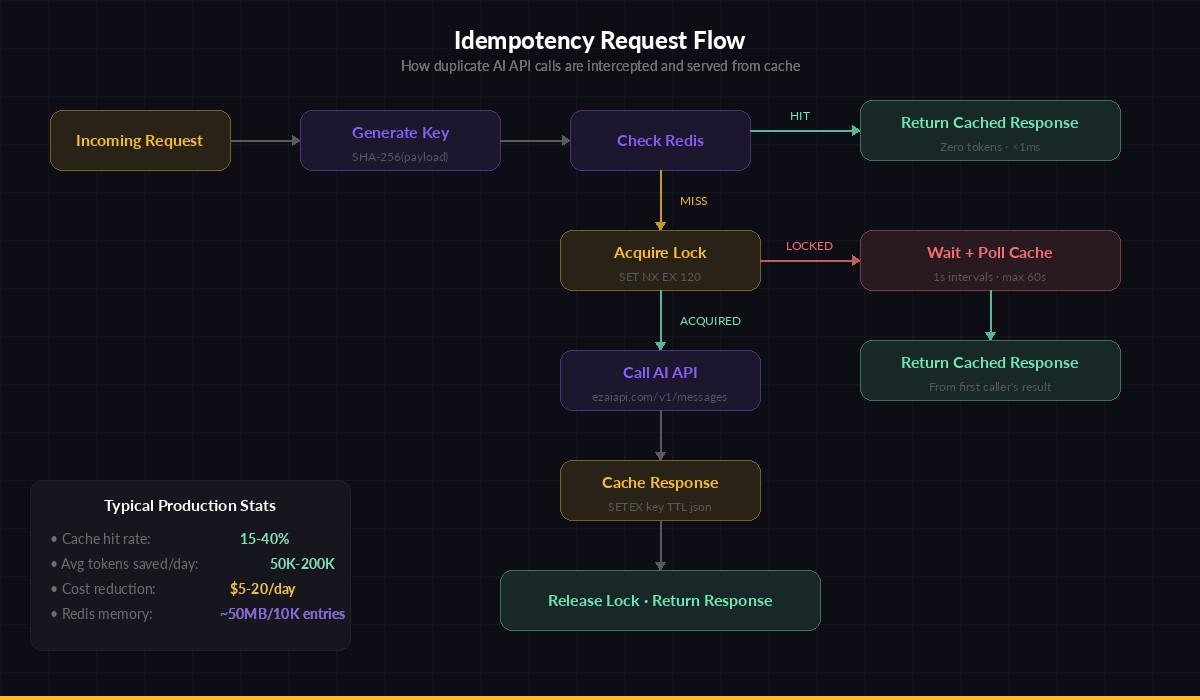
Request flow: check Redis → hit returns cached response, miss acquires lock → calls API → stores result
Handling Race Conditions with Locks
The naive check-then-call pattern has a gap: two identical requests arrive within milliseconds, both see a cache miss, and both call the API. You need a distributed lock to serialize concurrent duplicates:
import time
def idempotent_create(model, messages, max_tokens, system=None, ttl=3600):
key = make_idempotency_key(model, messages, max_tokens, system)
lock_key = f"{key}:lock"
# 1. Check cache
cached = r.get(key)
if cached:
return json.loads(cached) # Cache hit — free!
# 2. Acquire lock (NX = only if not exists, EX = 120s timeout)
acquired = r.set(lock_key, "1", nx=True, ex=120)
if not acquired:
# Another request is in-flight — wait for result
for _ in range(60):
time.sleep(1)
cached = r.get(key)
if cached:
return json.loads(cached)
raise TimeoutError("Idempotency lock timed out")
try:
# 3. Call the AI API
response = client.messages.create(
model=model,
max_tokens=max_tokens,
system=system or "",
messages=messages,
)
# 4. Cache the response
result = {
"content": response.content[0].text,
"model": response.model,
"usage": {
"input": response.usage.input_tokens,
"output": response.usage.output_tokens,
},
"cached_at": time.time(),
}
r.setex(key, ttl, json.dumps(result))
return result
finally:
r.delete(lock_key)The lock has a 120-second expiry as a safety net — if the process crashes mid-call, the lock auto-releases instead of blocking future requests forever. The waiting loop polls every second, which is fine for AI calls that typically take 2–30 seconds.
Choosing the Right TTL
TTL (time-to-live) depends on how your application uses AI responses:
- Code generation / analysis: 1–4 hours. Same code + same prompt = same review. Set
ttl=3600. - Chat / conversational: 5–15 minutes. Users expect fresh responses if they retry. Set
ttl=300. - Batch processing: 24 hours+. You're processing a dataset — duplicates should always return cached. Set
ttl=86400. - Retry-only dedup: 30–60 seconds. Only catch actual retries, not intentional re-asks. Set
ttl=60.
Integrating with EzAI API
Here's a complete wrapper class that plugs into any existing codebase using the Anthropic SDK with EzAI API:
import hashlib, json, time, logging
import redis, anthropic
log = logging.getLogger("idempotent_ai")
class IdempotentAI:
def __init__(self, api_key, redis_url="redis://localhost:6379/0",
default_ttl=3600):
self.client = anthropic.Anthropic(
api_key=api_key,
base_url="https://ezaiapi.com",
)
self.redis = redis.from_url(redis_url)
self.default_ttl = default_ttl
self.stats = {"hits": 0, "misses": 0, "saved_tokens": 0}
def create(self, model, messages, max_tokens=1024,
system=None, ttl=None, bypass=False):
if bypass:
return self._call_api(model, messages, max_tokens, system)
ttl = ttl or self.default_ttl
key = self._make_key(model, messages, max_tokens, system)
# Check cache
cached = self.redis.get(key)
if cached:
self.stats["hits"] += 1
data = json.loads(cached)
self.stats["saved_tokens"] += data["usage"]["input"] + data["usage"]["output"]
log.info(f"Idempotency HIT: {key[:20]} (saved {data['usage']['input']+data['usage']['output']} tokens)")
return data
self.stats["misses"] += 1
result = self._call_api(model, messages, max_tokens, system)
self.redis.setex(key, ttl, json.dumps(result))
return result
def _call_api(self, model, messages, max_tokens, system):
resp = self.client.messages.create(
model=model, messages=messages,
max_tokens=max_tokens, system=system or "",
)
return {
"content": resp.content[0].text,
"model": resp.model,
"usage": {"input": resp.usage.input_tokens,
"output": resp.usage.output_tokens},
}
def _make_key(self, model, messages, max_tokens, system):
raw = json.dumps({
"m": model, "msg": messages,
"mt": max_tokens, "s": system or "",
}, sort_keys=True)
return f"idem:{hashlib.sha256(raw.encode()).hexdigest()[:16]}"
# Usage
ai = IdempotentAI(api_key="sk-your-key")
# First call — hits the API
r1 = ai.create("claude-sonnet-4-5", [{"role": "user", "content": "Explain TCP handshake"}])
# Second call — same params, returns cached (zero cost)
r2 = ai.create("claude-sonnet-4-5", [{"role": "user", "content": "Explain TCP handshake"}])
print(ai.stats)
# {'hits': 1, 'misses': 1, 'saved_tokens': 847}The bypass=True flag lets you skip idempotency for specific calls — useful for conversational flows where repeated questions should genuinely get fresh answers.
Monitoring Your Savings
Track hit rates to quantify how much idempotency saves you. Add this endpoint to your cost dashboard:
# Add to your FastAPI/Flask app
@app.get("/metrics/idempotency")
def idempotency_metrics():
total = ai.stats["hits"] + ai.stats["misses"]
hit_rate = (ai.stats["hits"] / total * 100) if total else 0
# Rough cost estimate: $3/MTok input, $15/MTok output for Opus
saved_cost = ai.stats["saved_tokens"] * 0.000009
return {
"hit_rate_pct": round(hit_rate, 1),
"total_requests": total,
"cache_hits": ai.stats["hits"],
"tokens_saved": ai.stats["saved_tokens"],
"est_cost_saved_usd": round(saved_cost, 4),
}Edge Cases to Handle
Production idempotency layers need to account for a few gotchas:
- Temperature > 0: If you're using
temperature=0.7, identical inputs should produce different outputs. Only use idempotency withtemperature=0or accept that cached responses won't reflect randomness. For most production use cases (code gen, analysis, extraction),temperature=0is what you want anyway. - Streaming responses: You can't cache a stream mid-flight. Accumulate the full response, then cache it. Subsequent requests return the cached full response instantly — which is actually faster than streaming.
- Redis eviction: Set
maxmemory-policy allkeys-lruso Redis evicts least-recently-used keys when memory fills up. Idempotency keys are small (the response text is the bulk), so 1GB of Redis holds tens of thousands of cached responses. - Multi-region: If you run multiple regions, use a shared Redis cluster or accept per-region dedup. For most teams, per-region is fine — duplicates across regions are rare.
When Not to Use Idempotency
Skip the idempotency layer when:
- The AI call is part of an interactive chat and the user explicitly re-asked
- You're using high temperature for creative generation and need variety
- The response includes tool calls that trigger side effects (e.g., function calling that creates database records)
- You're already using prompt caching and the input token savings are sufficient
Idempotency and prompt caching solve different problems. Prompt caching reduces input token costs by reusing prefixes on the provider side. Idempotency prevents entire duplicate calls on your side. They stack well together — use both when it makes sense.
Wrapping Up
Adding idempotency to your AI API calls takes about 50 lines of Python and a Redis instance. The payoff is immediate: zero wasted spend on duplicate requests, faster responses for repeated queries, and cleaner retry logic throughout your stack. Start with a 1-hour TTL, monitor your hit rate on the EzAI dashboard, and adjust from there.
If you're running AI calls at scale, this is the lowest-effort, highest-impact optimization you can ship this week.