
AI API retry strategies separate production-grade applications from weekend projects. A single Claude or GPT call can fail for dozens of reasons — rate limits, overloaded servers, network timeouts, transient 500s — and your code needs to handle each one without crashing, hammering the server, or losing user data. This guide covers the three patterns that matter: exponential backoff, jitter, and circuit breakers.
Why Naive Retries Kill Your Application
The instinct is simple: if a request fails, try again. But immediate retries create a thundering herd. Imagine 200 concurrent users hit a rate limit at 14:32:01. All 200 retry at 14:32:01. All 200 fail again. They retry at 14:32:01. The server stays pinned, your app stays broken, and you've turned a 2-second blip into a 30-second outage.
This is the pattern that takes down production systems. The fix isn't complicated, but it requires understanding three distinct failure modes:
- 429 Too Many Requests — You're sending faster than the provider allows. The response usually includes a
Retry-Afterheader telling you exactly when to try again. - 500/502/503 — Server-side issues. These are almost always transient and resolve within seconds to minutes.
- Timeouts — Network issues or long-running inference. Claude Opus can take 60+ seconds on complex prompts; your 30-second timeout kills a perfectly valid request.
Exponential Backoff with Full Jitter
Exponential backoff increases wait time between retries: 1s, 2s, 4s, 8s. Jitter adds randomness so concurrent clients don't all retry at the same instant. The combination — exponential backoff with full jitter — is the gold standard recommended by AWS, Google Cloud, and every serious distributed systems team.
import random, time, httpx
def call_with_backoff(client, payload, max_retries=5):
for attempt in range(max_retries):
try:
resp = client.post(
"https://ezaiapi.com/v1/messages",
json=payload,
headers={
"x-api-key": "sk-your-key",
"anthropic-version": "2023-06-01",
"content-type": "application/json",
},
timeout=120.0,
)
if resp.status_code == 200:
return resp.json()
if resp.status_code == 429:
# Respect Retry-After header when present
wait = float(resp.headers.get("retry-after", 0))
if wait == 0:
wait = min(2 ** attempt, 60)
time.sleep(wait + random.uniform(0, 1))
continue
if resp.status_code >= 500:
# Server error — backoff with full jitter
cap = min(2 ** attempt, 30)
time.sleep(random.uniform(0, cap))
continue
# 400, 401, 403 — don't retry client errors
resp.raise_for_status()
except httpx.TimeoutException:
if attempt == max_retries - 1:
raise
time.sleep(random.uniform(0, 2 ** attempt))
raise Exception("Max retries exceeded")The key details that matter here: 429s use the server's Retry-After header when available, 500s use full jitter (not just decorrelated jitter), and client errors like 400 or 401 never retry because resending the same bad request won't fix an authentication issue.
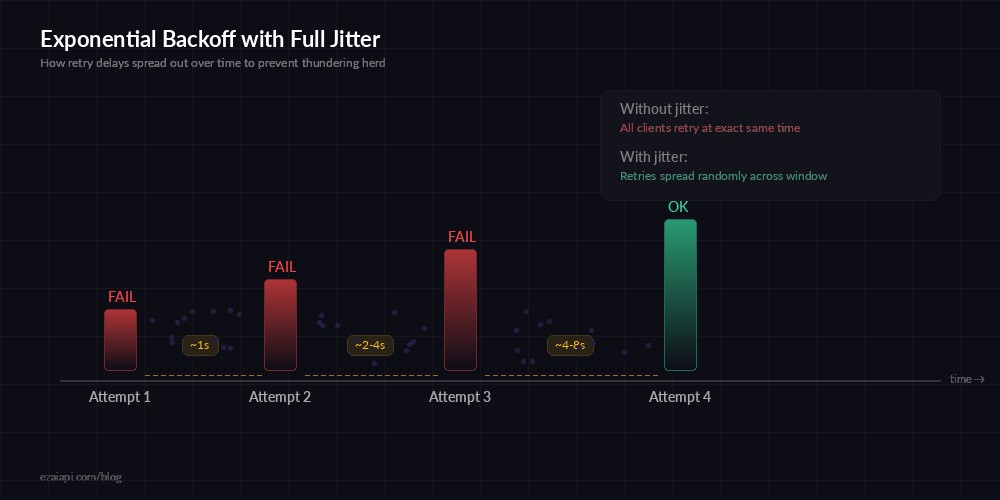
Exponential backoff with jitter spreads retries across time, preventing thundering herd
Circuit Breakers: Stop Hitting a Dead Server
Backoff handles transient failures. But what if the API is down for 10 minutes? Your retry logic will burn through attempts, queue up requests, and exhaust resources — all while sending traffic to a server that can't respond. A circuit breaker detects sustained failures and stops sending requests entirely until the service recovers.
The pattern has three states:
- Closed (normal) — Requests flow through. Track failure rate.
- Open (tripped) — Fail immediately without calling the API. No network traffic.
- Half-Open (probing) — Allow one test request. If it succeeds, close the circuit. If it fails, open it again.
import time, threading
class CircuitBreaker:
def __init__(self, failure_threshold=5, reset_timeout=60):
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.failures = 0
self.state = "closed"
self.last_failure = 0
self._lock = threading.Lock()
def can_execute(self):
with self._lock:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure > self.reset_timeout:
self.state = "half-open"
return True
return False
return True # half-open: allow probe
def record_success(self):
with self._lock:
self.failures = 0
self.state = "closed"
def record_failure(self):
with self._lock:
self.failures += 1
self.last_failure = time.time()
if self.failures >= self.failure_threshold:
self.state = "open"
# Usage with EzAI API
breaker = CircuitBreaker(failure_threshold=5, reset_timeout=60)
def resilient_call(client, payload):
if not breaker.can_execute():
raise Exception("Circuit open — API unavailable")
try:
result = call_with_backoff(client, payload)
breaker.record_success()
return result
except Exception:
breaker.record_failure()
raiseIn production, set failure_threshold between 3 and 10 depending on your traffic volume. High-throughput services use 3 to trip fast. Lower-volume apps can tolerate 5-10 before deciding the server is actually down versus just having a bad moment.
The Node.js Version
The same patterns translate directly to TypeScript. Here's a production-ready retry wrapper using the Anthropic SDK with EzAI:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: "sk-your-key",
baseURL: "https://ezaiapi.com",
});
async function callWithRetry(
params: Anthropic.MessageCreateParams,
maxRetries = 5
) {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await client.messages.create(params);
} catch (err: any) {
const status = err?.status;
// Don't retry client errors
if (status && status >= 400 && status < 500 && status !== 429) {
throw err;
}
if (attempt === maxRetries - 1) throw err;
// Exponential backoff with full jitter
const cap = Math.min(2 ** attempt, 30);
const delay = Math.random() * cap * 1000;
await new Promise((r) => setTimeout(r, delay));
}
}
}Handling Streaming Retries
Streaming adds a wrinkle: you might receive partial data before the connection drops. The key rule is never retry a partially-consumed stream without resetting your output buffer. Otherwise you end up with duplicated text in the response.
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
def stream_with_retry(params, max_retries=3):
for attempt in range(max_retries):
chunks = [] # Reset buffer on each attempt
try:
with client.messages.stream(**params) as stream:
for text in stream.text_stream:
chunks.append(text)
print(text, end="", flush=True)
return "".join(chunks)
except (anthropic.APIConnectionError, anthropic.APIStatusError) as e:
if attempt == max_retries - 1:
raise
print(f"\nStream interrupted, retrying ({attempt + 1}/{max_retries})...")
time.sleep(2 ** attempt)Notice that chunks = [] resets on each attempt. This is the most common streaming retry bug — developers append to the same buffer and end up with "Hello! How can IHello! How can I help you?" in the output.

Circuit breaker state machine — failures trip the circuit, timer probes for recovery
Production Checklist
Before you ship retry logic, walk through this list. Every production incident I've debugged around retry logic came from skipping one of these:
- Set sensible timeouts. Claude Opus with extended thinking can take 90+ seconds. Don't set a 30-second timeout on a model that needs a minute to think. With EzAI, you can use
timeout=120safely. - Never retry 400/401/403. If the request is malformed or your key is invalid, retrying is pointless and burns your rate limit quota.
- Log every retry. You need visibility into failure rates to tune your thresholds. A simple
logger.warning(f"Retry {attempt} after {status}")saves hours of debugging. - Add request IDs. EzAI returns
x-request-idin response headers. Log it. When you file a support ticket, this ID lets us trace exactly what happened to your request. - Use a fallback model. If Claude Opus is overloaded, fall back to Sonnet. EzAI gives you access to 20+ models through the same endpoint — use that flexibility.
- Set a retry budget. Cap total retry time at 2-3 minutes. If the API hasn't recovered in 3 minutes, it's not going to recover from retries — escalate to your monitoring system instead.
What EzAI Handles for You
One thing worth noting: EzAI's proxy layer already handles some retry scenarios transparently. When an upstream provider returns a transient error, EzAI can route your request to a healthy node automatically. You still want client-side retries for network issues between your app and EzAI, but the blast radius of provider-side failures is much smaller when you're behind a proxy that does its own health checking.
Combined with prompt caching (which means retried requests that hit cache cost nothing extra), the retry story with EzAI is significantly cheaper than going direct to providers.