
Sending a request to one AI model and waiting for a response is fine for prototypes. In production, you're leaving performance and reliability on the table. By firing requests at multiple models simultaneously — Claude, GPT, Gemini — you can take the fastest response, build consensus voting for accuracy-critical tasks, or get automatic failover when a provider goes down. All through EzAI's single endpoint.
This guide covers three parallel patterns that production teams actually use, with code you can drop into your stack today.
Why Parallel Requests Beat Sequential Calls
A single Claude Opus call takes 3-8 seconds depending on output length. GPT-5 sits around 2-6 seconds. Gemini 2.5 Pro runs 2-5 seconds. If you call them sequentially for a fallback chain, worst case you're looking at 19 seconds before your user sees a response.
Fire all three in parallel and your response time equals the fastest model, not the sum. That's typically 2-3 seconds — the same latency as a single call, but with fallback already baked in.
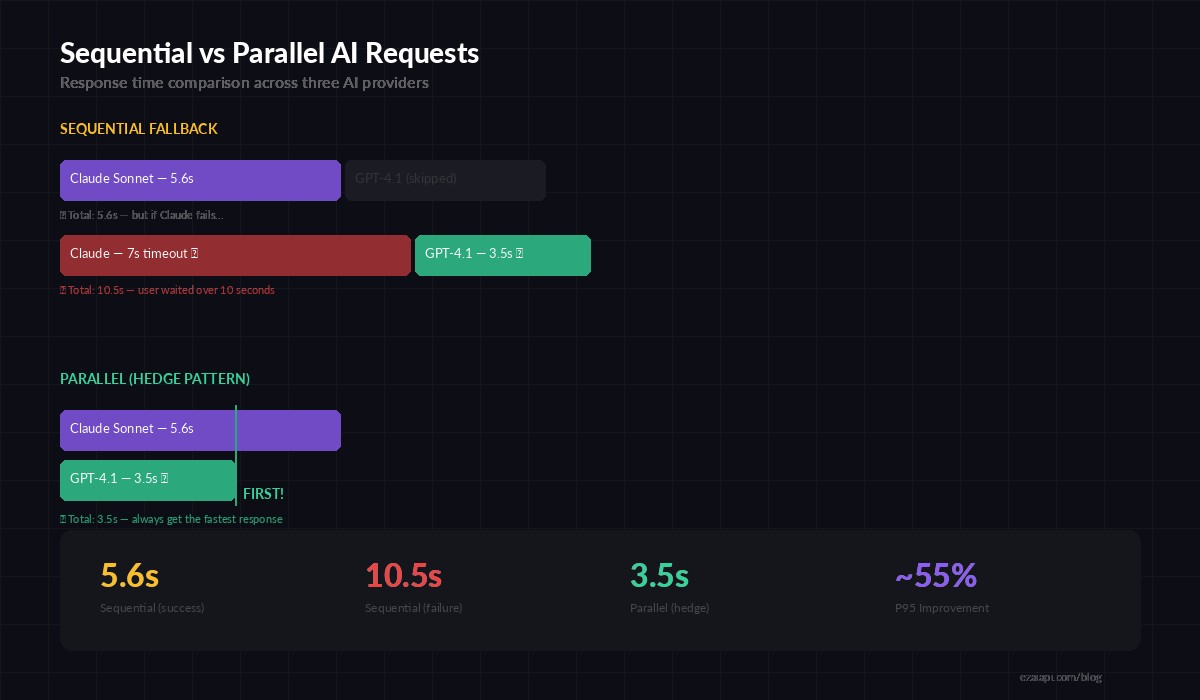
Sequential fallback adds latency on failure. Parallel requests keep your P95 flat.
The tradeoff is cost — you pay for all requests, not just the winning one. But for latency-sensitive paths (chat UIs, autocomplete, real-time agents), the extra $0.002 per request is worth saving 5+ seconds of user wait time.
Pattern 1: Race — First Response Wins
The simplest pattern. Fire identical requests at 2-3 models, take the first complete response, cancel the rest. Your effective latency becomes the minimum of all models instead of any single one.
import asyncio
import httpx
EZAI_KEY = "sk-your-key"
BASE_URL = "https://ezaiapi.com/v1/messages"
MODELS = ["claude-sonnet-4-5", "gpt-4.1", "gemini-2.5-pro"]
async def call_model(client, model, messages):
resp = await client.post(BASE_URL, json={
"model": model,
"max_tokens": 1024,
"messages": messages
}, headers={
"x-api-key": EZAI_KEY,
"anthropic-version": "2023-06-01",
"content-type": "application/json"
})
resp.raise_for_status()
data = resp.json()
return {"model": model, "text": data["content"][0]["text"]}
async def race(messages):
async with httpx.AsyncClient(timeout=30) as client:
tasks = [call_model(client, m, messages) for m in MODELS]
done, pending = await asyncio.wait(
[asyncio.create_task(t) for t in tasks],
return_when=asyncio.FIRST_COMPLETED
)
for t in pending:
t.cancel()
winner = done.pop().result()
print(f"Winner: {winner['model']} responded first")
return winner["text"]
# Usage
result = asyncio.run(race([{"role": "user", "content": "Explain JWT tokens in 3 sentences."}]))This works because EzAI normalizes the request format across providers. Same JSON body, same headers — the only thing that changes is the model field. No need to maintain separate SDKs or authentication flows.
Pattern 2: Consensus — Majority Vote for Accuracy
For tasks where correctness matters more than speed — code review, data extraction, classification — you want multiple models to agree. Send the same prompt to three models, collect all responses, and take the majority answer.
import asyncio, json
from collections import Counter
async def consensus_classify(text, categories):
prompt = f"""Classify this text into exactly one category.
Categories: {', '.join(categories)}
Text: {text}
Respond with JSON: {{"category": "chosen_category", "confidence": 0.0-1.0}}"""
messages = [{"role": "user", "content": prompt}]
async with httpx.AsyncClient(timeout=30) as client:
results = await asyncio.gather(
*[call_model(client, m, messages) for m in MODELS],
return_exceptions=True
)
votes = []
for r in results:
if isinstance(r, Exception):
continue
try:
parsed = json.loads(r["text"])
votes.append(parsed["category"])
except (json.JSONDecodeError, KeyError):
continue
if not votes:
raise ValueError("All models failed")
winner, count = Counter(votes).most_common(1)[0]
agreement = count / len(votes)
return {"category": winner, "agreement": agreement, "votes": votes}
# Example: 3 models vote on ticket classification
result = asyncio.run(consensus_classify(
"My payment was charged twice and I need a refund",
["billing", "technical", "feature_request", "general"]
))
# {"category": "billing", "agreement": 1.0, "votes": ["billing", "billing", "billing"]}When all three models agree, you have high confidence in the result. When they disagree, that's a signal the task is ambiguous — route it to a human reviewer or escalate to a more powerful model like Claude Opus.
Pattern 3: Hedge — Fallback Without the Wait
This is the pattern most production systems should default to. Pick a primary model (cheapest or fastest), fire it alongside a backup. If the primary succeeds within your latency budget, use it and discard the backup. If it fails or times out, the backup response is already waiting.
async def hedge_request(messages, primary="claude-sonnet-4-5",
backup="gpt-4.1-mini", budget_ms=3000):
async with httpx.AsyncClient(timeout=30) as client:
primary_task = asyncio.create_task(
call_model(client, primary, messages)
)
backup_task = asyncio.create_task(
call_model(client, backup, messages)
)
# Give primary the latency budget
try:
result = await asyncio.wait_for(
primary_task, timeout=budget_ms / 1000
)
backup_task.cancel()
return {**result, "source": "primary"}
except (asyncio.TimeoutError, Exception):
# Primary missed budget — use backup
try:
result = await backup_task
return {**result, "source": "backup"}
except Exception as e:
raise RuntimeError(f"Both models failed: {e}")
# Sonnet is primary, GPT-4.1 Mini is cheap backup
result = asyncio.run(hedge_request(
[{"role": "user", "content": "Summarize this PR diff..."}],
budget_ms=3000 # 3 second budget for primary
))
print(f"Response from {result['source']}: {result['model']}")The hedge pattern keeps your P95 latency tight. If Anthropic is having a slow day, your users don't notice because GPT was already running in the background. The extra cost is one cheap model call per request — usually under $0.001 with a mini model as backup.
Practical Considerations
Cost Control
Parallel requests multiply your spend. Keep it in check:
- Use cheaper models as backups — pair Claude Sonnet with GPT-4.1 Mini, not Opus with GPT-5
- Set
max_tokenslower for backup models if you only need a reasonable fallback - Use the race pattern only for latency-critical paths, not every API call
- Track per-model spend on your EzAI dashboard to catch cost spikes early
Error Handling Across Models
Each model can fail differently. Claude returns overloaded errors, OpenAI returns 429 rate limits, Gemini has its own error codes. With EzAI, error formats are normalized, but you still want return_exceptions=True in your asyncio.gather calls so one failure doesn't kill the entire batch.
Token Budget Alignment
Different models tokenize differently. A max_tokens: 1024 limit produces roughly the same output length, but token counts in your billing will vary. Monitor this on your usage dashboard during the first week to calibrate your cost estimates.
Full Production Example: Smart Router
Here's a complete router that picks the right pattern based on the task type. Classification gets consensus. Chat gets hedging. Code generation races for speed.
class SmartRouter:
def __init__(self, api_key):
self.key = api_key
self.strategies = {
"classify": self._consensus,
"chat": self._hedge,
"code": self._race,
}
async def route(self, task_type, messages):
strategy = self.strategies.get(task_type, self._hedge)
return await strategy(messages)
async def _consensus(self, messages):
# 3-model vote for classification accuracy
models = ["claude-sonnet-4-5", "gpt-4.1", "gemini-2.5-pro"]
async with httpx.AsyncClient(timeout=30) as c:
results = await asyncio.gather(
*[call_model(c, m, messages) for m in models],
return_exceptions=True
)
valid = [r for r in results if not isinstance(r, Exception)]
return valid[0] if valid else None
async def _hedge(self, messages):
# Primary + cheap backup for latency guarantee
return await hedge_request(messages,
primary="claude-sonnet-4-5",
backup="gpt-4.1-mini",
budget_ms=3000)
async def _race(self, messages):
# All models race for fastest code generation
return await race(messages)
# Usage
router = SmartRouter("sk-your-key")
result = asyncio.run(router.route("chat", [
{"role": "user", "content": "What's the best sorting algorithm for mostly-sorted data?"}
]))When Not to Parallelize
Parallel requests aren't always the answer. Skip them when:
- Streaming responses — you can't race streams easily since the first token doesn't mean the best output. Use streaming with a single model instead.
- Long-form generation — a 4000-token essay costs real money to generate 3x. Use sequential fallback for these.
- Rate-limited paths — if you're already hitting rate limits on one model, doubling your request volume makes it worse.
- Extended thinking tasks — models using extended thinking already take 10-30 seconds. Paralleling two of those is expensive for minimal latency gain.
Key Takeaways
Three parallel patterns, each for a different production need:
- Race — fastest response from any model. Best for latency-critical UIs.
- Consensus — majority voting across models. Best for classification and extraction accuracy.
- Hedge — primary with pre-warmed backup. Best default for most production apps.
EzAI makes this straightforward because all models share the same endpoint and request format. You don't need three API keys, three SDKs, or three auth flows. One key, one URL, swap the model name. Start with the hedge pattern on your most latency-sensitive endpoint and measure the impact — most teams see P95 latency drop by 40-60% on day one.