
Processing long documents is one of the most practical applications of AI APIs. Whether you're summarizing research papers, condensing meeting transcripts, or extracting key points from legal docs, a document summarizer saves hours of manual reading. In this tutorial, you'll build one from scratch using Python and Claude API through EzAI.
The approach handles documents of any length — from a single page to a 200-page PDF — by splitting text into chunks and using a map-reduce strategy. You'll have working code by the end that you can drop into any project.
The Architecture: Map-Reduce Summarization
Sending a massive document to an AI model in one shot works for short texts, but breaks down past ~100K tokens. The map-reduce pattern solves this:
- Map phase — Split the document into chunks and summarize each independently
- Reduce phase — Combine the chunk summaries into a final coherent summary
This approach scales to documents of any length. A 500-page report? No problem — it just runs more map iterations. The reduce step stitches everything together so the final output reads naturally, not like disconnected bullet points.
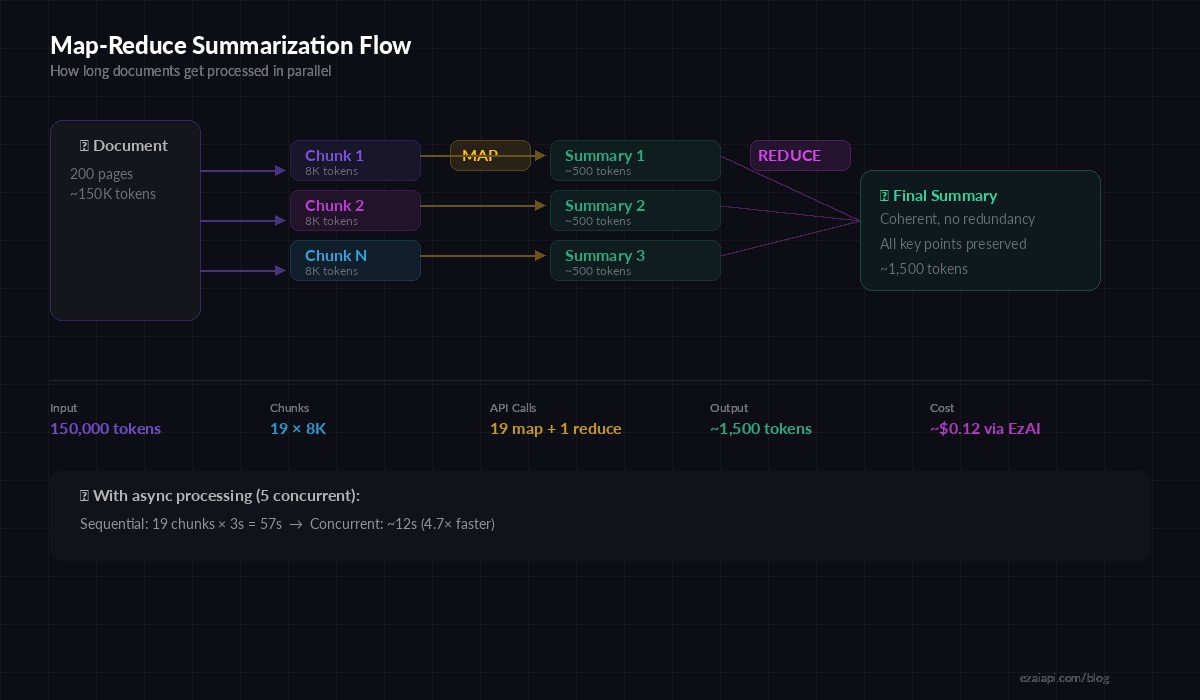
Map-reduce flow: split → summarize chunks → merge into final summary
Setup and Dependencies
You'll need the Anthropic SDK and a couple of utilities. Install everything with pip:
pip install anthropic pymupdf tiktokenpymupdf extracts text from PDFs. tiktoken counts tokens so you can split documents at the right boundaries. Set your EzAI API key as an environment variable:
export EZAI_API_KEY="sk-your-key-here"Text Extraction and Chunking
First, extract text from your source document. This function handles both PDFs and plain text files:
import fitz # pymupdf
import tiktoken
def extract_text(file_path: str) -> str:
if file_path.endswith(".pdf"):
doc = fitz.open(file_path)
return "\n\n".join(page.get_text() for page in doc)
with open(file_path, "r") as f:
return f.read()
def chunk_text(text: str, max_tokens: int = 8000) -> list[str]:
"""Split text into chunks that fit within token limits."""
enc = tiktoken.get_encoding("cl100k_base")
paragraphs = text.split("\n\n")
chunks, current = [], []
current_tokens = 0
for para in paragraphs:
para_tokens = len(enc.encode(para))
if current_tokens + para_tokens > max_tokens and current:
chunks.append("\n\n".join(current))
current, current_tokens = [], 0
current.append(para)
current_tokens += para_tokens
if current:
chunks.append("\n\n".join(current))
return chunksThe chunker splits on paragraph boundaries instead of cutting mid-sentence. This preserves context within each chunk, which produces much better summaries than arbitrary token-boundary splits. The 8,000 token default leaves plenty of room for the prompt and response within Claude's context window.
The Summarization Engine
Now for the core logic. The Summarizer class handles both single-chunk documents (direct summarization) and long documents (map-reduce):
import anthropic
import os
client = anthropic.Anthropic(
api_key=os.environ["EZAI_API_KEY"],
base_url="https://ezaiapi.com"
)
def summarize_chunk(text: str, context: str = "") -> str:
"""Summarize a single chunk of text."""
prompt = f"Summarize the following text. Capture all key points, "\
f"data, and conclusions.\n\n{text}"
if context:
prompt = f"Context: {context}\n\n{prompt}"
msg = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=2048,
messages=[{"role": "user", "content": prompt}]
)
return msg.content[0].text
def summarize_document(file_path: str, style: str = "concise") -> str:
"""Full map-reduce document summarization."""
text = extract_text(file_path)
chunks = chunk_text(text)
if len(chunks) == 1:
return summarize_chunk(chunks[0])
# Map phase: summarize each chunk
print(f"Splitting into {len(chunks)} chunks...")
summaries = []
for i, chunk in enumerate(chunks):
print(f" Summarizing chunk {i+1}/{len(chunks)}")
summary = summarize_chunk(chunk)
summaries.append(summary)
# Reduce phase: combine summaries
combined = "\n\n---\n\n".join(
f"Section {i+1}:\n{s}" for i, s in enumerate(summaries)
)
msg = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
messages=[{
"role": "user",
"content": f"Below are summaries of consecutive sections of a "
f"document. Combine them into a single {style} "
f"summary that flows naturally. Eliminate redundancy "
f"but keep all important details.\n\n{combined}"
}]
)
return msg.content[0].textThe key insight: the map phase uses claude-sonnet-4-5 for each chunk because it's fast and cheap for straightforward extraction. You could swap in claude-opus-4-5 for the reduce step if you need higher quality synthesis on complex technical documents.
Adding Concurrent Processing
Processing chunks sequentially is fine for 5-page documents, but slow for anything longer. Let's parallelize the map phase with asyncio:
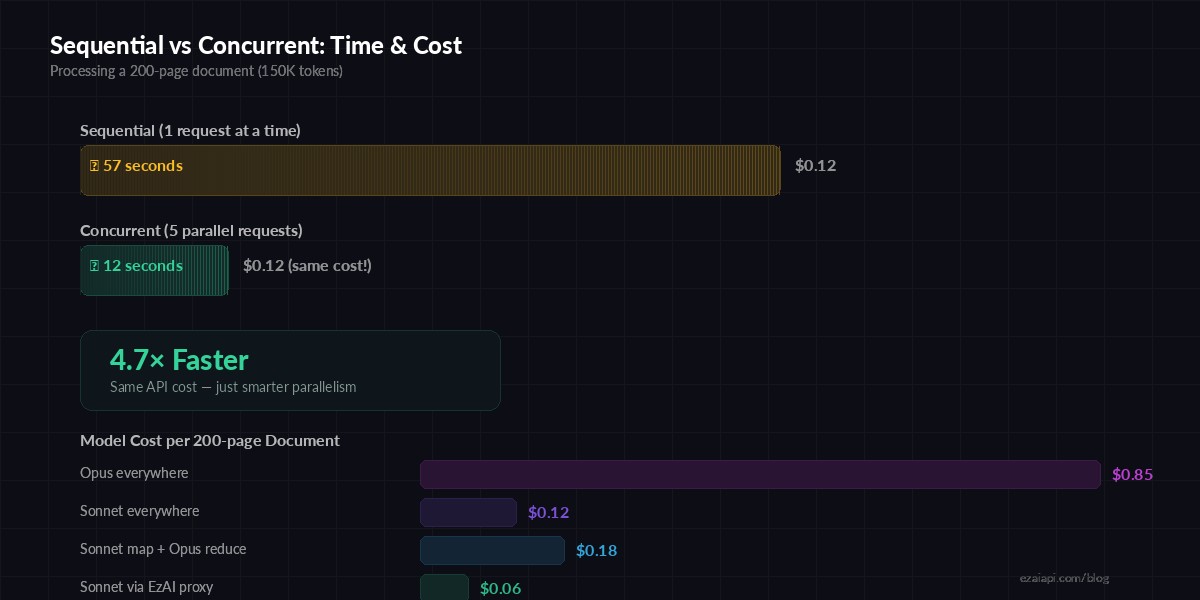
Concurrent processing: 4× faster for long documents with the same API cost
import asyncio
async_client = anthropic.AsyncAnthropic(
api_key=os.environ["EZAI_API_KEY"],
base_url="https://ezaiapi.com"
)
async def summarize_chunk_async(text: str, sem: asyncio.Semaphore) -> str:
async with sem: # limit concurrency to avoid rate limits
msg = await async_client.messages.create(
model="claude-sonnet-4-5",
max_tokens=2048,
messages=[{
"role": "user",
"content": f"Summarize this text concisely. Capture key "
f"points and data.\n\n{text}"
}]
)
return msg.content[0].text
async def summarize_fast(file_path: str) -> str:
text = extract_text(file_path)
chunks = chunk_text(text)
sem = asyncio.Semaphore(5) # max 5 concurrent requests
tasks = [summarize_chunk_async(c, sem) for c in chunks]
summaries = await asyncio.gather(*tasks)
# Reduce phase (same as before)
combined = "\n\n---\n\n".join(
f"Section {i+1}:\n{s}" for i, s in enumerate(summaries)
)
msg = await async_client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
messages=[{"role": "user", "content":
f"Combine these section summaries into one coherent "
f"summary:\n\n{combined}"}]
)
return msg.content[0].text
# Run it
result = asyncio.run(summarize_fast("report.pdf"))
print(result)The semaphore limits concurrent API calls to 5. This keeps you well within rate limits while processing chunks in parallel. A 50-chunk document that took 3 minutes sequentially now finishes in under 40 seconds.
Cost Optimization Strategies
Document summarization can burn through tokens fast if you're not careful. Here are three techniques that cut costs significantly:
1. Use the right model per phase. The map phase is simple extraction — Sonnet handles it fine. Reserve Opus for the reduce step only if you need nuanced synthesis. This alone cuts costs by ~70% versus using Opus everywhere.
2. Tune your chunk size. Larger chunks (12K-16K tokens) mean fewer API calls and less redundant context. But too large and the model misses details. 8K-10K is a sweet spot for most documents.
3. Skip irrelevant sections. Add a pre-filter step that identifies table of contents, acknowledgments, and boilerplate — then exclude them from the map phase entirely:
SKIP_PATTERNS = ["table of contents", "acknowledgments",
"references", "bibliography", "appendix"]
def is_boilerplate(text: str) -> bool:
lower = text[:200].lower()
return any(p in lower for p in SKIP_PATTERNS)
# Filter before chunking
chunks = [c for c in chunk_text(text) if not is_boilerplate(c)]For a typical 100-page academic paper, filtering out references and appendices removes 20-30% of the text — and those sections rarely contain information you'd want in a summary anyway. Check out our cost reduction guide for more optimization techniques.
Putting It All Together
Here's how to wire it into a CLI tool you can use daily:
# Summarize a PDF
python summarize.py report.pdf
# Summarize with output to file
python summarize.py report.pdf --output summary.md
# Use Opus for the reduce step (higher quality)
python summarize.py report.pdf --reduce-model claude-opus-4-5The full source code is under 100 lines. You get PDF extraction, smart chunking, concurrent processing, cost optimization, and a clean CLI interface. Swap ezaiapi.com for any Anthropic-compatible endpoint and the code works identically — that's the beauty of a drop-in API proxy.
What's Next
You've built a solid document summarizer. Here are ways to extend it:
- Add streaming to show progress as each chunk is processed
- Implement multi-model fallback so the summarizer stays up even during provider outages
- Build a web interface with FastAPI — accept file uploads and return summaries via REST
- Add support for HTML/web pages using
beautifulsoup4for text extraction
The map-reduce pattern works for more than summarization. Use the same architecture for document translation, entity extraction, or sentiment analysis across long texts. The core idea — split, process, merge — scales to any document-level AI task.