
At some point, every AI-backed app learns the same lesson the hard way: the model will go down. Anthropic will have an incident. OpenAI will rate-limit you during a launch. Your single cloud region will have packet loss. If your app's response to any of those is a red toast saying Internal Server Error, you've outsourced your availability to a vendor's status page.
Graceful degradation is the pattern for surviving that. The idea is simple: instead of one response path that either succeeds or 502s, you define a ladder of reduced-quality fallbacks. Users get something useful — maybe slower, cheaper, or slightly stale — instead of nothing. This post walks through the tier model, the fallback chain in Python, and how to wire it up with EzAI's unified endpoint so you're not juggling four SDKs.
Why "just retry" isn't enough
Retries handle transient noise — a dropped TCP connection, a 503 from an overloaded pod. They don't help when the entire region is down or a model family has been deprecated mid-request. They also make correlated failures worse: a thundering herd of retries during an incident prolongs the outage for everyone on the same shard. If you haven't already, pair this guide with our retry strategies writeup — retries are the inner loop, degradation is the outer one.
Real resilience needs three things: detection (fast enough to not block the user), alternatives (ranked by quality and cost), and a floor (something that always works, even if it's dumb). The tier diagram below is how we usually lay it out.
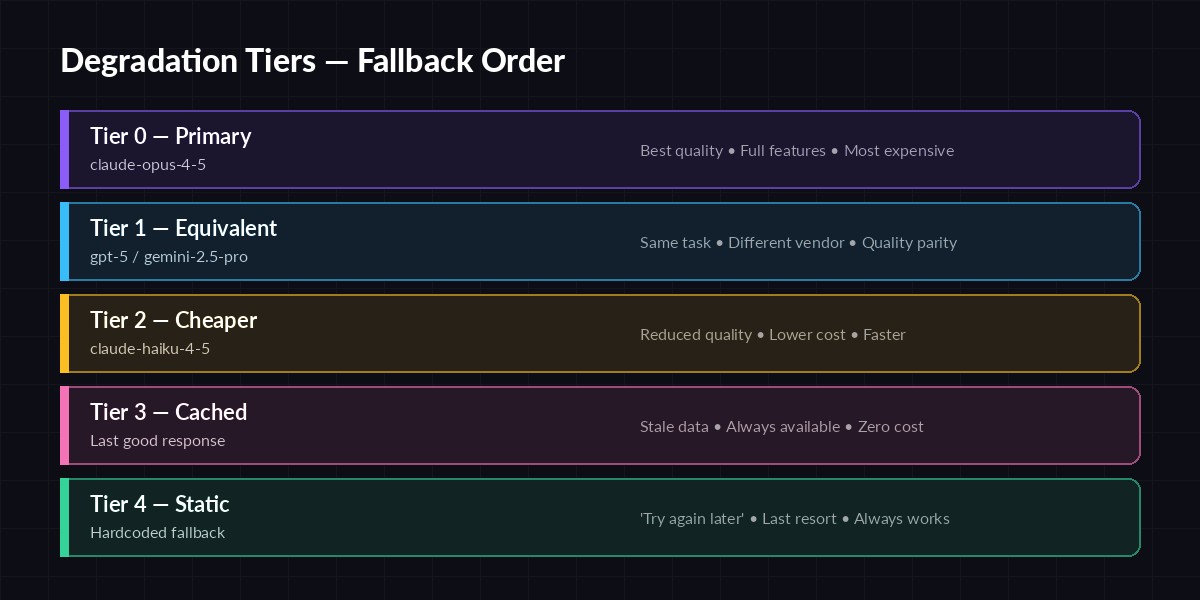
Five tiers, ordered by quality. Each tier catches failures the one above can't handle.
Degradation Tiers
You don't need all five tiers on day one, but you should have at least three (primary, cheaper, and static). Here's how to think about each:
- Tier 0 — Primary: Your best model.
claude-opus-4-5for reasoning,gpt-5for vision, whatever your product was designed around. - Tier 1 — Cross-vendor equivalent: A different vendor's flagship at similar quality. Protects against vendor-specific incidents.
- Tier 2 — Cheaper/faster model: Lower quality but still useful. Great for non-critical calls during partial outages or cost spikes.
- Tier 3 — Cached response: The last successful answer to the same (or semantically similar) input. See caching AI responses for the storage side.
- Tier 4 — Static fallback: A hardcoded response. "We're experiencing issues — please try again in a few minutes." It's not glamorous but it keeps your app out of the error state.
A Fallback Chain in Python
Here's a minimal but production-shaped chain. It uses EzAI's Anthropic-compatible endpoint so one SDK covers both Tier 0 and Tier 1 — you just change the model field.
import time, logging, hashlib
from anthropic import Anthropic, APIStatusError, APIConnectionError
client = Anthropic(api_key="sk-your-key", base_url="https://ezaiapi.com")
log = logging.getLogger("ai.degradation")
TIERS = [
{"name": "primary", "model": "claude-opus-4-5", "timeout": 30},
{"name": "cross-vendor","model": "gpt-5", "timeout": 30},
{"name": "cheap", "model": "claude-haiku-4-5", "timeout": 15},
]
def call_tier(tier, messages):
return client.messages.create(
model=tier["model"],
max_tokens=1024,
messages=messages,
timeout=tier["timeout"],
)
def generate_with_fallback(messages, cache):
key = hashlib.sha256(str(messages).encode()).hexdigest()
for tier in TIERS:
try:
resp = call_tier(tier, messages)
cache[key] = resp.content[0].text # refresh Tier 3
return {"text": resp.content[0].text, "tier": tier["name"]}
except (APIStatusError, APIConnectionError, TimeoutError) as e:
log.warning("tier %s failed: %s", tier["name"], e)
continue
# Tier 3: cached
if key in cache:
return {"text": cache[key], "tier": "cached", "stale": True}
# Tier 4: static
return {"text": "Our AI is temporarily unavailable. Please retry in a minute.",
"tier": "static"}
Two things worth flagging. First, the per-tier timeout goes down as you descend — you don't want to spend 30s on each of five tiers before giving up. Second, every fallback is logged with the tier name, which is critical for the SLO work in the next section.
Measuring Degraded Traffic
If you don't measure it, you won't notice when Tier 0 is quietly failing 40% of the time. Emit a counter for every response with a tier label:
from prometheus_client import Counter
AI_RESP = Counter(
"ai_responses_total",
"AI responses by degradation tier",
["tier", "endpoint"],
)
result = generate_with_fallback(messages, cache)
AI_RESP.labels(tier=result["tier"], endpoint="/chat").inc()
Now you can set an alert like "page me if Tier 0 share drops below 95% for 5 minutes". Combine it with proper monitoring and you'll hear about model regressions before your users do.
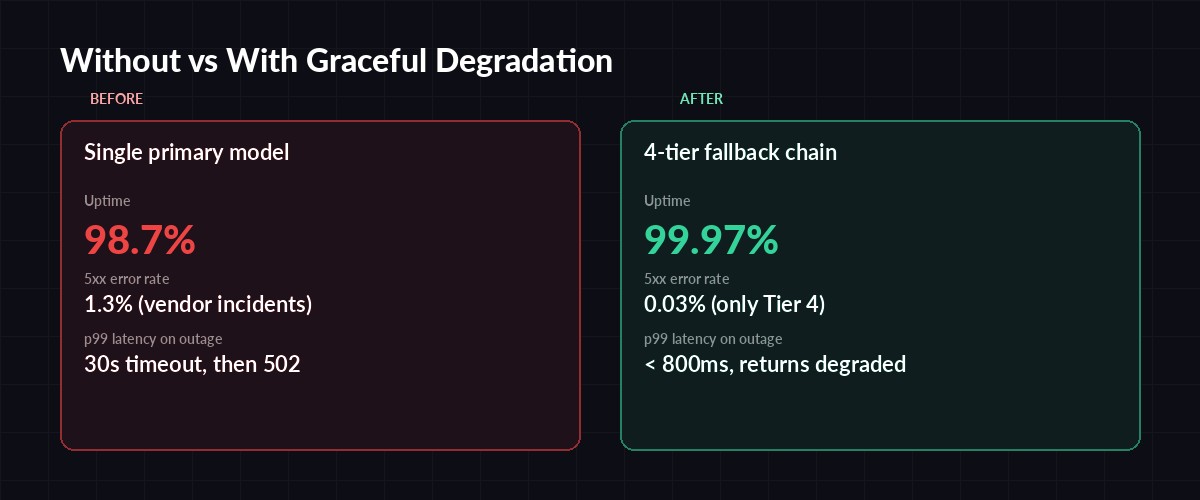
Same app, same incident — only the fallback chain is different.
UX During Degradation
Graceful means the user notices less, not the user notices nothing. A few rules we've landed on:
- Label stale data. If you serve a cached answer, say so: "Last updated 3 min ago." Users forgive a stale result; they don't forgive a confident wrong one.
- Disable heavy features, don't hide them. If vision is down, grey out the image upload with a tooltip, don't just remove it — removing the button makes users refresh and think their app is broken.
- Never lie about the tier. If a call came from
haiku, don't let the UI claim it wasopus. This matters especially if you expose model choice to users (see our routing strategy guide).
Testing the Fallbacks
A fallback you've never exercised in production is a fallback that doesn't work. Two cheap ways to test without waiting for a real outage:
- Chaos mode in staging: randomly inject failures on Tier 0 with a 20% probability. Make sure the p99 latency and user-facing output stay acceptable.
- Scheduled drills: force Tier 0 off for 10 minutes once a week during business hours. Real traffic, real metrics. Netflix popularized this; the Simian Army post is still a good read.
If you want a production safety net without writing a custom chaos harness, EzAI exposes forced-failure headers on a staging key so you can simulate vendor outages from your test suite. Combine that with multi-model fallback at the proxy layer and you get two independent degradation paths — application-level and network-level.
Wrap-up
Graceful degradation isn't one feature; it's a habit. Start with three tiers, emit the tier label on every response, set one alert, and run one drill. You'll claw back several nines of availability from a component (the model) that you fundamentally don't control. Your users won't send you a thank-you email when your app keeps working during the next outage — that's the point.
If you'd rather not wire four SDKs together, a single EzAI key gets you Claude, GPT, Gemini, and Grok on one Anthropic-compatible endpoint, which makes Tier 0 → Tier 1 a one-line change instead of a refactor.