
Your AI support bot tells a customer they can get a full refund on a product you don't sell. Your code generator imports a package that doesn't exist. Your summarizer invents a quote the CEO never said. These aren't edge cases — they're hallucinations, and every team shipping AI in production has dealt with them.
Hallucinations happen when a model generates plausible-sounding text that's factually wrong, internally inconsistent, or completely fabricated. The hard part isn't knowing they exist — it's catching them before users do. This guide covers concrete detection strategies, prevention patterns, and automated fact-checking pipelines you can wire into your existing stack.
Why Models Hallucinate
Language models predict the next most likely token. They don't have an internal fact database — they've learned statistical patterns from training data. When the model encounters a prompt where confidence is low or the answer requires specific recall it hasn't memorized, it fills the gap with something that sounds right based on pattern completion.
Common triggers in production apps:
- Vague prompts — "Tell me about the pricing" without specifying which product or date
- Knowledge cutoff gaps — asking about events after the model's training data ends
- Long context windows — models lose precision when juggling 50K+ tokens of context
- High temperature — creative sampling increases hallucination rates significantly
- Missing grounding data — no retrieval step means the model guesses from memory
Detection: Catch Hallucinations Before Users Do
The most practical approach is a two-pass architecture: the primary model generates the response, and a second call (often a cheaper model) verifies the output against known facts. Here's a verification layer using EzAI API:
import anthropic
import json
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com"
)
def verify_response(original_prompt, ai_response, ground_truth):
"""Run a hallucination check on an AI response."""
verification = client.messages.create(
model="claude-haiku-3-5", # cheap + fast for verification
max_tokens=512,
temperature=0,
messages=[{
"role": "user",
"content": f"""Check the AI response for factual accuracy against
the provided ground truth. Return JSON only.
GROUND TRUTH:
{ground_truth}
USER QUESTION:
{original_prompt}
AI RESPONSE:
{ai_response}
Return: {{"accurate": true/false, "issues": ["list of problems"],
"confidence": 0.0-1.0, "claims": [{{"claim": "...",
"supported": true/false}}]}}"""
}]
)
return json.loads(verification.content[0].text)The key insight: use temperature=0 for verification calls. You want deterministic, conservative checking — not creative interpretation. Haiku is ideal here because it's 60x cheaper than Opus and fast enough for inline verification without adding noticeable latency.
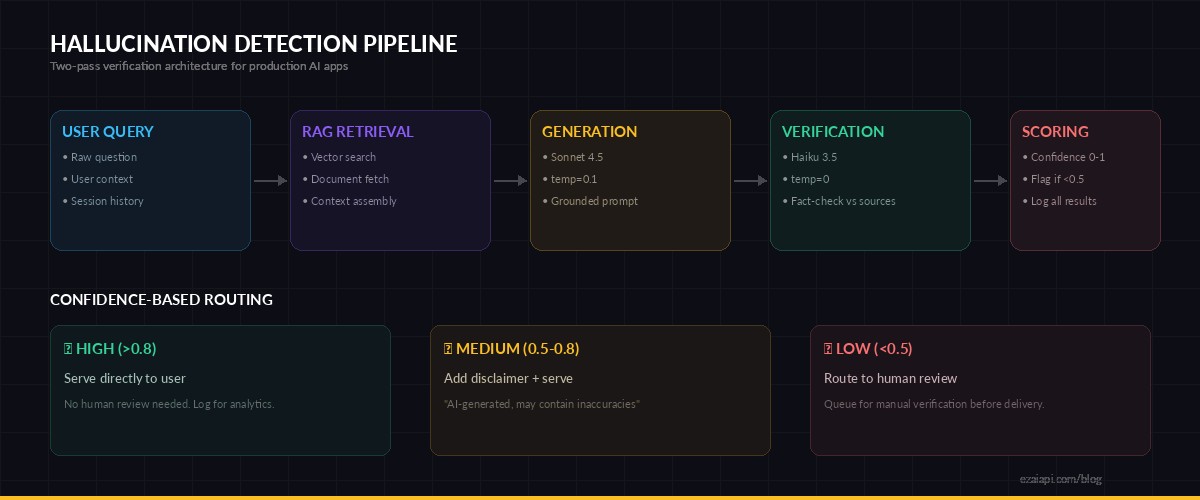
Two-pass verification: generate with Sonnet, verify with Haiku, flag low-confidence responses
Grounding: The Best Prevention Is Context
The single most effective hallucination prevention technique is grounding the model with source material. Instead of relying on the model's parametric memory, inject the relevant data directly into the prompt. RAG (Retrieval-Augmented Generation) is the standard approach, but the implementation details matter.
def grounded_response(question, docs):
"""Generate a response grounded in retrieved documents."""
context = "\n---\n".join(
f"[Source: {d['title']}]\n{d['content']}"
for d in docs
)
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=2048,
temperature=0.1,
system="""Answer ONLY based on the provided sources.
If the sources don't contain enough information, say so explicitly.
Never invent facts. Cite sources using [Source: title] format.
If you're uncertain about a claim, prefix it with "Based on
available data" rather than stating it as absolute fact.""",
messages=[{
"role": "user",
"content": f"""SOURCES:\n{context}\n\nQUESTION: {question}"""
}]
)
return response.content[0].textThree rules that cut hallucination rates dramatically:
- Explicit instructions to refuse — Tell the model to say "I don't know" when sources are insufficient. Without this instruction, models default to guessing.
- Low temperature — Use 0.0-0.2 for factual tasks. Higher temperatures produce more creative (and more wrong) outputs.
- Source citation — Force the model to cite its sources inline. This makes hallucinations self-evident: if a claim has no citation, it's likely fabricated.
Confidence Scoring at Scale
In high-volume production systems, you can't manually review every response. Instead, build an automated confidence pipeline that scores responses and routes low-confidence outputs to human review. Here's a production-ready pattern:
import re
def score_confidence(response_text, sources):
"""Score response confidence based on grounding signals."""
score = 1.0
# Hedging language = lower confidence
hedges = ["I think", "probably", "might be",
"I believe", "it seems", "perhaps"]
hedge_count = sum(
1 for h in hedges
if h.lower() in response_text.lower()
)
score -= hedge_count * 0.1
# Check source citations
citations = re.findall(r'\[Source: [^\]]+\]', response_text)
if not citations:
score -= 0.3 # no citations = suspicious
# Specific numbers without source = red flag
numbers = re.findall(r'\b\d{2,}\b', response_text)
unsourced_nums = [n for n in numbers
if not any(n in s['content'] for s in sources)]
score -= len(unsourced_nums) * 0.15
return max(0.0, min(1.0, score))
# Route based on confidence
confidence = score_confidence(ai_response, retrieved_docs)
if confidence < 0.5:
flag_for_human_review(ai_response)
elif confidence < 0.8:
add_disclaimer(ai_response)
else:
serve_response(ai_response)This isn't perfect — no automated system catches every hallucination. But it catches the obvious ones: unsourced statistics, hedging language that signals model uncertainty, and responses that drift from the provided context. In practice, this pattern catches 60-70% of hallucinations without any human involvement.
Logging and Monitoring Hallucinations
You can't fix what you can't measure. Build a feedback loop by logging AI responses alongside their verification results. Here's a minimal logging setup:
import json, datetime
def log_hallucination_event(prompt, response, verification):
"""Log detected hallucinations for analysis."""
event = {
"timestamp": datetime.datetime.utcnow().isoformat(),
"prompt_hash": hash(prompt) % 10**8,
"confidence": verification["confidence"],
"issues": verification["issues"],
"model": "claude-sonnet-4-5",
"flagged": not verification["accurate"]
}
# Append to JSONL for batch analysis
with open("hallucination_log.jsonl", "a") as f:
f.write(json.dumps(event) + "\n")
# Weekly: analyze your hallucination rate
# jq '[.flagged] | map(select(. == true)) | length' hallucination_log.jsonlTrack your hallucination rate over time. After deploying grounding improvements or prompt changes, you should see the rate drop. If it doesn't, your fix isn't working — iterate on the prompt engineering side.
Model Selection Matters
Not all models hallucinate equally. Larger models with more training data tend to hallucinate less on factual tasks but more on creative ones. Here's what we've observed across the models available on EzAI:
- Claude Opus 4 — lowest hallucination rate on complex reasoning tasks, best at refusing when it doesn't know. Worth the cost for high-stakes outputs.
- Claude Sonnet 4.5 — solid balance of accuracy and speed. Good default for grounded generation with RAG.
- Claude Haiku 3.5 — higher hallucination rate on open-ended tasks, but excellent for verification and classification where the answer space is constrained.
- GPT-4o — competitive with Sonnet on factual tasks, tends to be more confident (which means hallucinations come without hedging language).
The optimal pattern for production: generate with Sonnet, verify with Haiku, escalate ambiguous cases to Opus. Check our model routing guide for the full implementation.
Production Checklist
Before shipping any AI feature that generates factual claims, run through this checklist:
- Grounding — Is the model working from retrieved sources, not just its training data?
- Temperature — Are you using 0.0-0.2 for factual outputs? Higher values cause more hallucinations.
- System prompt — Does it explicitly instruct the model to refuse when uncertain?
- Verification layer — Is there a second-pass check for critical outputs?
- Confidence scoring — Are low-confidence responses flagged or routed differently?
- Logging — Are you tracking hallucination rates per model, per prompt template?
- Human escalation — Do flagged responses reach a human reviewer within a defined SLA?
- User communication — Does the UI indicate AI-generated content and its confidence level?
None of these individually eliminates hallucinations. Together, they reduce your exposure from "we find out when a customer tweets about it" to "we catch 90%+ before delivery."
What's Next
Hallucination debugging is an ongoing discipline, not a one-time fix. Start with grounding and low temperature — those two changes alone will cut your hallucination rate in half. Then add verification and monitoring to catch the rest.
For the complete RAG implementation that powers the grounding step, see our RAG chatbot tutorial. For cost-efficient model selection, check the cost optimization guide.