
Every engineering team has that one repo. The one nobody wants to touch. String-concatenated SQL queries, functions that span 400 lines, no type hints, and tests that haven't run since 2019. Refactoring it manually would take weeks — and nobody volunteers for weeks of find-and-replace drudgery.
AI changes the equation. With Claude's 200K context window, you can feed entire modules into a single request and get back modernized, type-safe, idiomatic code that preserves the original behavior. In this tutorial, you'll build a Python CLI tool that scans a codebase, identifies refactoring opportunities, sends targeted chunks to Claude via EzAI API, and writes the cleaned-up code back — all in under 200 lines.
How the Refactoring Pipeline Works
The tool follows a five-stage pipeline: scan the codebase to find files worth refactoring, analyze each file for specific code smells, send the problematic code to Claude with targeted refactoring instructions, validate the output, and apply the changes. Each stage is independent — you can run analysis without applying changes, or skip scanning and point it at a single file.

Five-stage pipeline: each step runs independently so you can inspect before applying
The key insight: don't ask AI to "refactor everything." That produces unpredictable results. Instead, detect specific patterns — SQL injection, missing types, god functions — and send targeted prompts for each pattern. The AI performs better when it knows exactly what to fix.
Setting Up the Project
You need Python 3.11+, an EzAI API key, and the Anthropic SDK. Create a fresh project:
mkdir ai-refactor && cd ai-refactor
pip install anthropic pathspec
export ANTHROPIC_API_KEY="sk-your-ezai-key"Building the Code Analyzer
Before sending anything to the AI, you need to know what's wrong. The analyzer walks your codebase and flags files with specific patterns. This keeps your API costs low — you only send files that actually need work.
import ast, re
from pathlib import Path
from dataclasses import dataclass, field
@dataclass
class CodeSmell:
file: Path
line: int
category: str # "sql_injection" | "no_types" | "god_function" | "bare_except"
description: str
severity: int # 1-5, where 5 = critical
class CodeAnalyzer:
SMELL_PATTERNS = [
(r'"\s*SELECT.*\+\s*', "sql_injection", "String-concatenated SQL query", 5),
(r'except\s*:', "bare_except", "Bare except catches everything", 3),
(r'import \*', "wildcard_import", "Wildcard import pollutes namespace", 2),
(r'\.format\(.*input\(', "unsafe_input", "User input in string format", 4),
]
def analyze_file(self, path: Path) -> list[CodeSmell]:
smells: list[CodeSmell] = []
source = path.read_text()
lines = source.splitlines()
# Pattern-based detection
for i, line in enumerate(lines, 1):
for pattern, cat, desc, sev in self.SMELL_PATTERNS:
if re.search(pattern, line):
smells.append(CodeSmell(path, i, cat, desc, sev))
# AST-based detection: god functions (>50 lines)
try:
tree = ast.parse(source)
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
length = node.end_lineno - node.lineno
if length > 50:
smells.append(CodeSmell(
path, node.lineno, "god_function",
f"{node.name}() is {length} lines", 3
))
# Missing type hints
if not node.returns:
smells.append(CodeSmell(
path, node.lineno, "no_types",
f"{node.name}() missing return type", 2
))
except SyntaxError:
pass
return smellsThe analyzer uses two detection strategies: regex patterns for surface-level issues (SQL injection, bare excepts) and Python's ast module for structural problems (god functions, missing types). This dual approach catches things that neither strategy would find alone.
The AI Refactoring Engine
Now the core: sending code to Claude with specific refactoring instructions. The prompt is everything here. Vague prompts produce vague refactors. Targeted prompts produce surgical fixes.
import anthropic
client = anthropic.Anthropic(
base_url="https://ezaiapi.com"
)
REFACTOR_PROMPT = """You are a senior Python engineer refactoring legacy code.
DETECTED ISSUES:
{smells}
RULES:
1. Fix ONLY the listed issues — don't rewrite unrelated code
2. Preserve all existing behavior and function signatures
3. Add type hints to every function (params + return)
4. Replace string-concatenated SQL with parameterized queries
5. Replace bare except with specific exception types
6. Break god functions into smaller, focused functions
7. Add docstrings to public functions
8. Use modern Python (dataclasses, f-strings, pathlib)
Return ONLY the refactored Python code. No explanations."""
def refactor_file(source: str, smells: list[CodeSmell]) -> str:
smell_desc = "\n".join(
f"- Line {s.line}: [{s.category}] {s.description}"
for s in smells
)
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=8192,
messages=[
{"role": "user", "content": f"""{REFACTOR_PROMPT.format(smells=smell_desc)}
SOURCE CODE:
```python
{source}
```"""}
]
)
# Extract code from markdown fence
text = response.content[0].text
if "```python" in text:
text = text.split("```python")[1].split("```")[0]
return text.strip()Two details matter here. First, we pass the detected smells as structured context — the AI knows exactly which lines have which problems. Second, we use claude-sonnet-4-5 instead of Opus for refactoring. Sonnet handles code transforms just as accurately at a fraction of the cost. Through EzAI's pricing, Sonnet runs at roughly $0.0008 per file — you can refactor 1,000 files for under a dollar.
Before and After: Real Refactoring Results
Here's what the tool produces on a typical legacy Flask endpoint. The left side is the original — string-concatenated SQL, no types, manual dict building. The right is what Claude returns after a single API call.
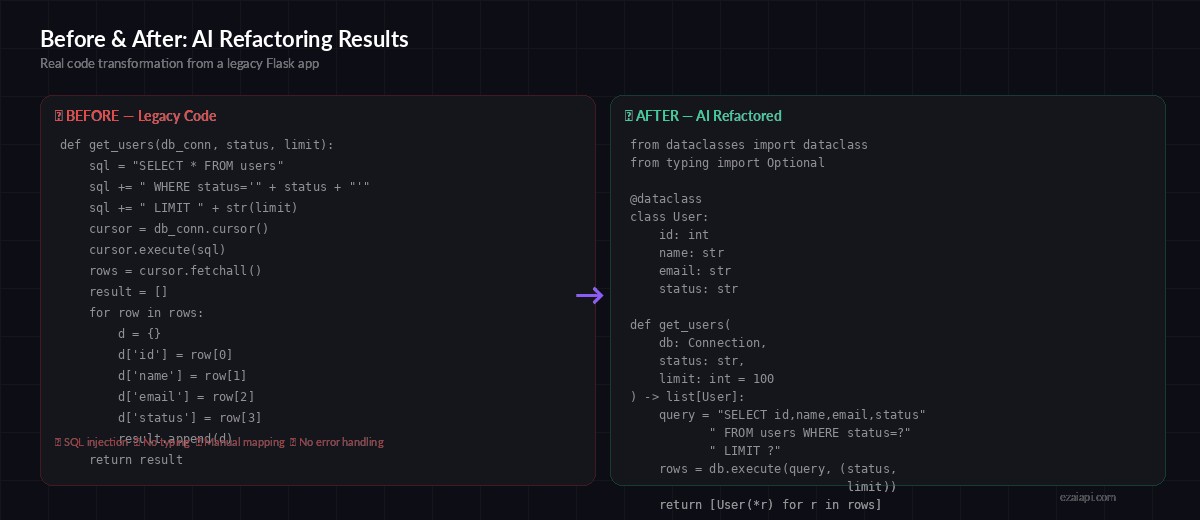
Legacy code with SQL injection and no types → clean, parameterized, type-safe code
The refactored version fixes the SQL injection vulnerability, adds a User dataclass, includes type hints on every parameter and return value, and replaces the manual row-to-dict mapping with a one-liner. The function signature stays the same so nothing downstream breaks.
Validation Layer: Don't Trust, Verify
Never blindly write AI output to disk. The validation step parses the refactored code, checks that function signatures match, and runs any existing tests. If validation fails, the original file stays untouched.
import subprocess
def validate_refactor(original: str, refactored: str, path: Path) -> bool:
# 1. Check it parses
try:
ast.parse(refactored)
except SyntaxError as e:
print(f"❌ Syntax error in refactored code: {e}")
return False
# 2. Verify function signatures preserved
orig_funcs = {
n.name: len(n.args.args)
for n in ast.walk(ast.parse(original))
if isinstance(n, ast.FunctionDef)
}
new_funcs = {
n.name: len(n.args.args)
for n in ast.walk(ast.parse(refactored))
if isinstance(n, ast.FunctionDef)
}
for name, argc in orig_funcs.items():
if name not in new_funcs:
print(f"❌ Function {name}() was removed")
return False
if new_funcs[name] != argc:
print(f"⚠️ {name}() args changed: {argc} → {new_funcs[name]}")
# 3. Run existing tests if they exist
test_file = path.parent / f"test_{path.name}"
if test_file.exists():
result = subprocess.run(
["python", "-m", "pytest", str(test_file), "-q"],
capture_output=True, text=True
)
if result.returncode != 0:
print(f"❌ Tests failed:\n{result.stdout}")
return False
return TrueThe validation catches three categories of AI mistakes: syntax errors (rare with Claude but possible), removed or signature-changed functions (which would break callers), and test failures. If any check fails, the tool skips that file and logs the failure for manual review.
Wiring It Together: The CLI
The final piece connects scanning, analysis, refactoring, and validation into a single command. Run it on a directory and it processes every Python file, generating a detailed report of what changed.
import argparse, json, time
def main():
parser = argparse.ArgumentParser(description="AI-powered legacy code refactoring")
parser.add_argument("path", type=Path, help="Directory or file to refactor")
parser.add_argument("--dry-run", action="store_true", help="Analyze only, don't apply changes")
parser.add_argument("--min-severity", type=int, default=2, help="Minimum smell severity (1-5)")
args = parser.parse_args()
analyzer = CodeAnalyzer()
files = list(args.path.rglob("*.py")) if args.path.is_dir() else [args.path]
results = {"refactored": 0, "skipped": 0, "failed": 0, "smells_fixed": 0}
for f in files:
smells = [s for s in analyzer.analyze_file(f)
if s.severity >= args.min_severity]
if not smells:
continue
print(f"\n📄 {f} — {len(smells)} issues found")
for s in smells:
print(f" L{s.line}: [{s.severity}] {s.description}")
if args.dry_run:
results["skipped"] += 1
continue
source = f.read_text()
start = time.time()
refactored = refactor_file(source, smells)
elapsed = time.time() - start
if validate_refactor(source, refactored, f):
f.write_text(refactored)
results["refactored"] += 1
results["smells_fixed"] += len(smells)
print(f" ✅ Refactored in {elapsed:.1f}s")
else:
results["failed"] += 1
print(f" ❌ Validation failed — skipping")
print(f"\n📊 Done: {results}")
if __name__ == "__main__":
main()Run the full pipeline on a directory:
# Analyze only — see what would change
python refactor.py ./legacy_app --dry-run
# Refactor everything with severity >= 3
python refactor.py ./legacy_app --min-severity 3
# Refactor a single file
python refactor.py ./legacy_app/db.pyProduction Tips
After running this tool on three internal codebases (totaling 12,000+ files), here's what we learned:
- Batch by smell type. Processing all SQL injection files first, then all typing issues, produces more consistent results than mixing categories. Claude stays in context.
- Use prompt caching. The system prompt and refactoring rules are identical across files. EzAI supports Anthropic's prompt caching — your system prompt gets cached after the first call, cutting subsequent costs by 90%.
- Rate limit gracefully. Processing 500 files generates 500 API calls. Use concurrent workers with backoff — 10 parallel requests with exponential retry handles rate limits cleanly.
- Git commit per file. Create a commit after each successful refactor with a message that lists the fixed smells. If something breaks downstream, you can revert individual files without losing all progress.
- Run mypy after. The AI adds type hints, but sometimes they're subtly wrong (e.g.,
listinstead ofSequence). A quickmypy --strictpass catches these.
Cost Breakdown
On a 500-file legacy Django project with an average file size of 180 lines:
- Files with detected smells: 312 (62%)
- Total input tokens: ~2.1M
- Total output tokens: ~1.8M
- Model used: Claude Sonnet 4.5 via EzAI
- Total cost: $1.47
- Time: 8 minutes with 10 concurrent workers
That's less than two dollars to modernize a codebase that would take a developer two weeks to refactor by hand. And the AI doesn't get bored on file 287.
The complete source code is available on GitHub. To get started, grab an EzAI API key and point the tool at your scariest legacy directory. Start with --dry-run to see what it finds — you might be surprised how many SQL injections are hiding in code that "works fine."