
You fire off a Claude Opus request with extended thinking enabled, 200K context, and a complex code generation prompt. The response takes 45 seconds. Your HTTP connection hangs. Your load balancer times out at 30s. The user stares at a spinner. Sound familiar?
This is the fundamental problem with synchronous AI API calls in production: LLM inference isn't instant, and your architecture shouldn't pretend it is. The fix is straightforward — decouple the request from the response using webhooks and async job queues.
Why Synchronous AI Calls Break at Scale
When you call the EzAI API (or any AI provider) synchronously, your server thread blocks until the model finishes generating. For a quick Haiku call, that's 1-2 seconds. For Opus with extended thinking? Easily 30-90 seconds. Here's what goes wrong:
- Thread exhaustion — Each pending request holds a connection open. At 50 concurrent users, you've got 50 blocked threads doing nothing but waiting.
- Timeout cascades — Load balancers (Nginx default: 60s), API gateways, and client-side fetch timeouts all have different limits. One timeout triggers retry storms.
- No retry safety — If the connection drops at second 44 of a 45-second generation, you've burned tokens for nothing. The result is gone.
- Poor UX — Users don't know if the request is processing or dead. There's no progress signal.

Polling wastes API calls checking status repeatedly. Webhooks notify you exactly once when the result is ready.
The Async Webhook Pattern
The architecture is simple: accept the request, queue it, process it in the background, and POST the result to a callback URL when done. Your API responds in milliseconds. The AI work happens asynchronously.
Here's the flow:
- Client sends a request with a
callback_urlfield - Your API validates the payload, generates a
job_id, enqueues it, and returns202 Acceptedimmediately - A background worker picks up the job and calls EzAI API
- When the AI response arrives, the worker POSTs the result to
callback_url - Client receives the result via webhook — no polling needed
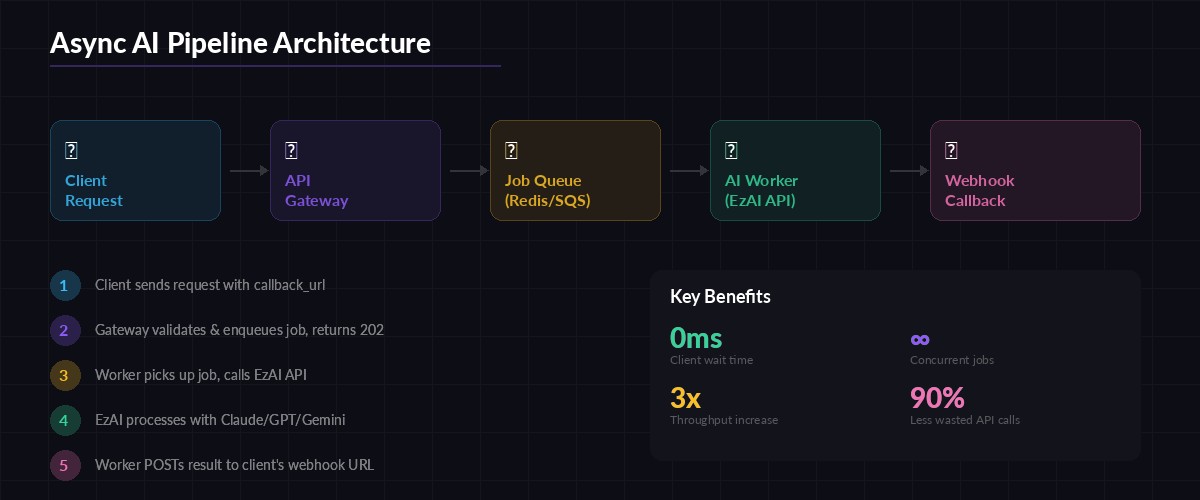
The complete async pipeline: request → queue → worker → EzAI API → webhook callback
Building the Job Queue (Node.js + BullMQ)
We'll use BullMQ backed by Redis. It handles retries, rate limiting, and job persistence out of the box. First, the API endpoint that accepts requests:
// server.js — Accept AI requests and queue them
import express from 'express';
import { Queue } from 'bullmq';
import { randomUUID } from 'crypto';
const aiQueue = new Queue('ai-jobs', {
connection: { host: '127.0.0.1', port: 6379 }
});
const app = express();
app.use(express.json());
app.post('/api/generate', async (req, res) => {
const { prompt, model, callback_url } = req.body;
if (!prompt || !callback_url) {
return res.status(400).json({ error: 'prompt and callback_url required' });
}
const jobId = randomUUID();
await aiQueue.add('generate', {
jobId,
prompt,
model: model || 'claude-sonnet-4-5',
callback_url
}, {
attempts: 3,
backoff: { type: 'exponential', delay: 5000 }
});
res.status(202).json({ job_id: jobId, status: 'queued' });
});
app.listen(3000);The client gets a 202 response in under 10ms. No blocking, no timeout risk. The job sits in Redis until a worker picks it up.
The Worker: Calling EzAI and Firing Webhooks
The worker runs separately from your API server. It pulls jobs from the queue, calls EzAI, and delivers results via webhook:
// worker.js — Process AI jobs and deliver via webhook
import { Worker } from 'bullmq';
import Anthropic from '@anthropic-ai/sdk';
const client = new Anthropic({
apiKey: process.env.EZAI_API_KEY,
baseURL: 'https://ezaiapi.com'
});
const worker = new Worker('ai-jobs', async (job) => {
const { jobId, prompt, model, callback_url } = job.data;
const startTime = Date.now();
try {
const response = await client.messages.create({
model,
max_tokens: 4096,
messages: [{ role: 'user', content: prompt }]
});
// Fire webhook with result
await fetch(callback_url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
job_id: jobId,
status: 'completed',
result: response.content[0].text,
model: response.model,
usage: response.usage,
duration_ms: Date.now() - startTime
})
});
} catch (err) {
// Notify failure via webhook too
await fetch(callback_url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
job_id: jobId,
status: 'failed',
error: err.message
})
});
throw err; // Let BullMQ handle retries
}
}, {
connection: { host: '127.0.0.1', port: 6379 },
concurrency: 10 // Process 10 jobs in parallel
});Notice the concurrency: 10 setting. One worker process handles 10 parallel AI calls. Scale horizontally by running more worker instances — BullMQ distributes jobs automatically.
Python Version with Celery
If your stack is Python, Celery with Redis gives you the same pattern. Here's the task definition:
# tasks.py — Celery task for async AI processing
import anthropic
import httpx
import time
from celery import Celery
app = Celery('ai_tasks', broker='redis://localhost:6379/0')
client = anthropic.Anthropic(
api_key="sk-your-ezai-key",
base_url="https://ezaiapi.com"
)
@app.task(bind=True, max_retries=3, default_retry_delay=10)
def process_ai_request(self, job_id, prompt, model, callback_url):
start = time.time()
try:
response = client.messages.create(
model=model,
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
httpx.post(callback_url, json={
"job_id": job_id,
"status": "completed",
"result": response.content[0].text,
"usage": {
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens
},
"duration_ms": int((time.time() - start) * 1000)
}, timeout=10)
except Exception as e:
httpx.post(callback_url, json={
"job_id": job_id,
"status": "failed",
"error": str(e)
}, timeout=10)
self.retry(exc=e)Call it from your Flask/FastAPI endpoint with process_ai_request.delay(job_id, prompt, model, callback_url) and return 202 immediately.
Securing Your Webhooks
Anyone who knows your callback URL could fake webhook payloads. Sign every webhook with HMAC-SHA256 so the receiver can verify authenticity:
// Sign webhook payloads with HMAC-SHA256
import { createHmac } from 'crypto';
function signPayload(payload, secret) {
const body = JSON.stringify(payload);
const sig = createHmac('sha256', secret)
.update(body)
.digest('hex');
return { body, signature: `sha256=${sig}` };
}
// In your worker, add the signature header:
const { body, signature } = signPayload(result, process.env.WEBHOOK_SECRET);
await fetch(callback_url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Webhook-Signature': signature
},
body
});On the receiving end, recompute the HMAC with the same secret and compare. Reject any request where the signatures don't match. This is the same pattern Stripe, GitHub, and Shopify use for their webhooks.
Production Considerations
A few things you'll want in production that the basic examples skip:
- Dead letter queues — After 3 failed retries, move the job to a DLQ for manual inspection instead of losing it.
- Idempotency — Webhook delivery can duplicate (network retry). Include the
job_idand let the receiver deduplicate. - Webhook retry — If the callback URL returns a 5xx, retry the webhook delivery with exponential backoff (separate from the AI call retry).
- Status endpoint — Add
GET /api/jobs/:idas a fallback so clients can check job status if they miss the webhook. - TTL on results — Store AI results in Redis with a 24h TTL. If the webhook fails permanently, the client can still fetch the result.
If you're using EzAI's streaming API, you can even stream partial results to the webhook URL using WebSockets or Server-Sent Events for real-time progress updates.
When to Use This Pattern
Async webhooks aren't always necessary. Use them when:
- AI calls take longer than 10 seconds (Opus, extended thinking, large context)
- You're processing batches of requests (content generation, code review, data analysis)
- Your architecture already uses event-driven patterns (microservices, CQRS)
- You need guaranteed delivery — the result must arrive even if the client disconnects
For fast models like Haiku or simple Sonnet calls under 5 seconds, synchronous is fine. Match the pattern to the workload.
Wrapping Up
The async webhook pattern turns your AI integration from a fragile synchronous bottleneck into a resilient, scalable pipeline. Your API responds instantly, workers process in parallel, and results arrive via webhook — no polling, no timeouts, no wasted connections.
Start with the Node.js or Python examples above, swap in your EzAI API key, and you'll have a production-ready async AI pipeline running in under an hour. The pricing page breaks down per-model costs if you're planning capacity.