
AI API pricing has shifted dramatically in early 2026. Anthropic launched Claude Opus 4 and Sonnet 4.5 with extended thinking. OpenAI pushed GPT-5 and o3-mini into production. Google shipped Gemini 2.5 Pro with a million-token context window. And xAI's Grok 3 entered the mix at aggressive price points. For developers building on these APIs, understanding the current pricing landscape isn't optional — it directly impacts your infrastructure budget.
This guide breaks down what each provider charges per million tokens, where the real value lies, and how to use a proxy like EzAI to access all of them through a single endpoint at reduced cost.
The Current Pricing Landscape
Here's what you're paying per million tokens across the major providers as of March 2026. These are direct API prices — what you'd pay going straight to each provider:
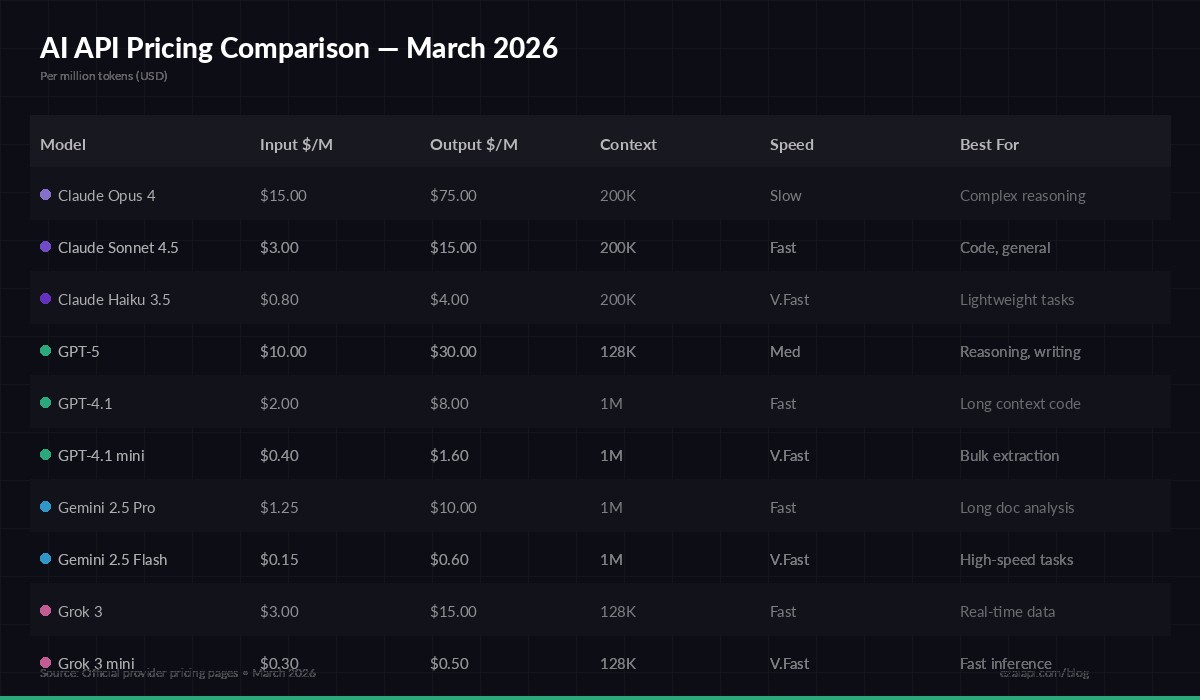
Per-million-token pricing across major AI providers (March 2026)
The spread is massive. Claude Opus 4 costs $15/M input, $75/M output — the most expensive option — but it's also the strongest reasoning model available. Meanwhile, GPT-4.1 mini runs at $0.40/M input, $1.60/M output, making it 37x cheaper on output than Opus. Gemini 2.5 Flash sits in the middle at $0.15/M input, $0.60/M output for standard requests.
Cost Per Task: What Actually Matters
Raw per-token pricing tells you half the story. What matters is cost per completed task. A cheaper model that needs three retries costs more than an expensive model that nails it the first time.
Here's a real example. Say you're building a code review bot that analyzes pull requests. A typical PR diff is about 2,000 tokens input and you need ~800 tokens of output:
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com" # Route through EzAI
)
def review_pr(diff: str) -> str:
"""Review a PR diff — Sonnet 4.5 handles this well."""
response = client.messages.create(
model="claude-sonnet-4-5-20250514",
max_tokens=1024,
messages=[{
"role": "user",
"content": f"Review this PR diff for bugs, security issues, and style:\n\n{diff}"
}]
)
return response.content[0].textCost per review with different models:
- Claude Opus 4: $0.09 per review — overkill for most PRs
- Claude Sonnet 4.5: $0.018 per review — excellent quality, reasonable cost
- GPT-4.1 mini: $0.002 per review — cheap but misses subtle bugs
- Gemini 2.5 Flash: $0.0008 per review — fastest, good for linting-level checks
The smart move? Use model routing — send simple PRs to Flash, complex ones to Sonnet, and only escalate security-critical reviews to Opus.
Extended Thinking: The Hidden Cost Multiplier
Extended thinking (chain-of-thought reasoning) is powerful, but it inflates costs significantly. When you enable thinking on Claude, the model generates internal reasoning tokens that you pay for at output rates.
A request that normally produces 500 output tokens might generate 3,000+ thinking tokens on top of that. At Sonnet 4.5's output rate of $10/M, those extra thinking tokens add $0.03 per request.
# Extended thinking — use only when the task demands reasoning
response = client.messages.create(
model="claude-sonnet-4-5-20250514",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # Cap thinking to control costs
},
messages=[{
"role": "user",
"content": "Analyze this algorithm for time complexity edge cases..."
}]
)
# Check how many thinking tokens were used
print(f"Thinking tokens: {response.usage.thinking_tokens}")
print(f"Output tokens: {response.usage.output_tokens}")Set budget_tokens to cap thinking costs. For most tasks, 5,000–10,000 thinking tokens is enough. Check our extended thinking guide for a deeper breakdown of when it's worth enabling.
The Proxy Advantage: Why Direct API Is Leaving Money on the Table
Going directly to each provider means managing separate API keys, separate billing, and separate rate limits. With a proxy like EzAI, you get tangible cost savings on top of the operational simplification:
- Lower per-token rates — EzAI aggregates volume across users, passing bulk pricing to you
- One API key — access Claude, GPT, Gemini, and Grok through
ezaiapi.com - Built-in caching — identical requests hit cache instead of the upstream API
- Fallback routing — if one provider is down, requests automatically route to an alternative
- Free tier — 3 models at zero cost for prototyping and low-volume use
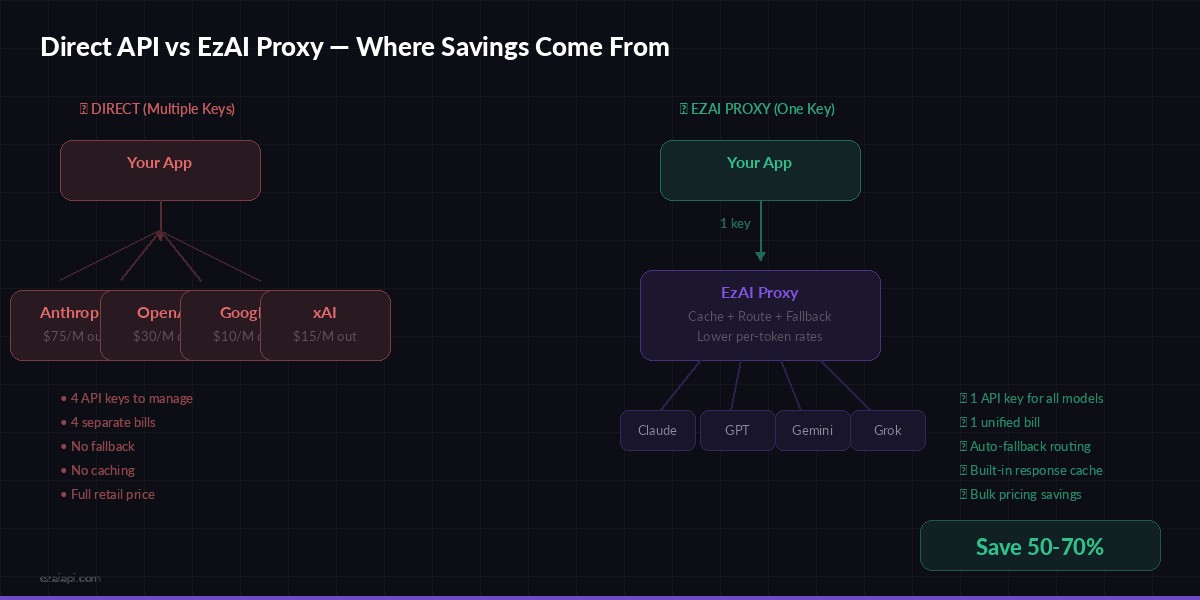
Direct API vs EzAI proxy — where savings come from
Switching to EzAI takes one line of code. Here's a Node.js example:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: "sk-your-ezai-key",
baseURL: "https://ezaiapi.com", // Only change needed
});
const msg = await client.messages.create({
model: "claude-sonnet-4-5-20250514",
max_tokens: 1024,
messages: [{ role: "user", content: "Explain quicksort in 3 sentences." }],
});
console.log(msg.content[0].text);Which Model Should You Actually Use?
Forget picking "the best model." Pick the right model for each task. Here's a practical decision framework based on current pricing and capability:
- Chatbots / customer support: Gemini 2.5 Flash or GPT-4.1 mini — fast, cheap, good enough for conversational tasks
- Code generation: Claude Sonnet 4.5 — best code quality at a reasonable price point
- Complex reasoning: Claude Opus 4 with extended thinking — expensive but unmatched for multi-step logic
- Summarization / extraction: GPT-4.1 mini or Gemini Flash — structured output tasks don't need frontier models
- Long documents (100K+ tokens): Gemini 2.5 Pro — million-token context at competitive pricing
Teams running production AI workloads typically use 2–3 models in combination. Route each request to the cheapest model that can handle it reliably. We covered this pattern in detail in our model routing strategy guide.
Practical Cost Optimization Checklist
Here's what actually moves the needle on your monthly AI bill:
- Cache identical requests — a simple hash-based cache cuts costs 40–60% on repeated queries
- Use smaller models by default — only escalate to Opus/GPT-5 when the task fails on Sonnet/4.1
- Set token limits — always specify
max_tokensto prevent runaway output - Cap thinking budgets — don't let extended thinking burn 50K tokens on a simple question
- Batch where possible — Anthropic's batch API gives 50% off, and EzAI supports it
- Monitor per-model spend — use your EzAI dashboard to spot cost spikes early
Most teams that implement these six strategies see a 50–70% reduction in their monthly API costs without any quality degradation. The biggest win is usually #2 — most requests don't need a $75/M output model.
The Bottom Line
AI API pricing in 2026 rewards teams that treat model selection as an engineering decision, not a one-time choice. The gap between the cheapest and most expensive models is nearly 200x on output tokens, and that gap is only growing as providers ship more specialized tiers.
Start with a proxy like EzAI to access every model through a single endpoint, route intelligently based on task complexity, and cache aggressively. Your token budget will stretch a lot further.
Ready to cut your AI API costs? Sign up for EzAI — it takes 2 minutes, and every new account gets 15 free credits to try all models.