
Your AI-powered feature works perfectly in development. Then you ship it, and within 48 hours you're staring at a dashboard full of 500 errors, 429 rate limits, and mysterious timeouts. Every AI API fails eventually — the question is whether your code handles it gracefully or dumps a stack trace on your users.
This guide covers the three pillars of production-grade AI API resilience: intelligent retries, timeout tuning, and model fallbacks. Every example uses ezaiapi.com as the endpoint, but the patterns apply to any provider.
Why AI APIs Fail Differently Than REST APIs
Traditional REST APIs return in milliseconds. AI APIs can take 5–60 seconds for a single response, depending on the model, input length, and whether you're using extended thinking. That changes the failure calculus:
- Rate limits (429) hit harder because each request is expensive — you've already spent tokens on the prompt
- Timeouts are ambiguous — did the model stall, or is it just thinking deeply about your 100k-token context?
- Overload errors (529) are provider-side and mean the entire model is saturated, not just your account
- Partial responses can arrive via streaming and then die mid-sentence, leaving you with half an answer
You can't treat these like a failed database query. You need a strategy for each failure mode.
Exponential Backoff with Jitter
The most common mistake: retrying immediately after a 429. That just adds more load to an already overloaded system. Exponential backoff with jitter spreads retry attempts across time, giving the API breathing room.
import anthropic
import random
import time
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
def call_with_retry(messages, model="claude-sonnet-4-5", max_retries=4):
for attempt in range(max_retries):
try:
return client.messages.create(
model=model,
max_tokens=2048,
messages=messages,
)
except anthropic.RateLimitError:
if attempt == max_retries - 1:
raise
# Exponential backoff: 1s, 2s, 4s + random jitter
base_delay = 2 ** attempt
jitter = random.uniform(0, base_delay * 0.5)
time.sleep(base_delay + jitter)
except anthropic.APIStatusError as e:
if e.status_code == 529: # Overloaded
time.sleep(5 + random.uniform(0, 5))
continue
raise # Don't retry 400s or auth errorsKey details: we only retry on 429 (rate limit) and 529 (overload). Retrying a 400 (bad request) or 401 (auth failure) is pointless — those won't self-resolve. The jitter prevents the thundering herd problem where all your retry timers fire simultaneously.

Which errors to retry and which to fail fast — the decision tree for AI API error codes
Timeout Tuning: The Goldilocks Problem
Set the timeout too low and you'll kill requests that were about to succeed. Set it too high and your users stare at a spinner for 90 seconds before seeing an error. Here's how to size it by use case:
- Quick completions (chatbot replies, classifications): 30 seconds
- Complex generation (code, long-form writing): 60 seconds
- Extended thinking (Claude with
thinkingenabled): 120–180 seconds - Large context (100k+ tokens input): 90–120 seconds
import httpx
import anthropic
# Per-request timeout control
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
timeout=httpx.Timeout(
connect=5.0, # TCP connect timeout
read=120.0, # Read timeout (waiting for response)
write=10.0, # Write timeout (sending request)
pool=10.0, # Connection pool timeout
),
)
# Override per-call for fast operations
quick_response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=256,
messages=[{"role": "user", "content": "Classify: positive or negative"}],
timeout=httpx.Timeout(connect=5.0, read=30.0, write=10.0, pool=10.0),
)The connect timeout should always be low (3–5 seconds). If the TCP handshake takes longer than that, the server is probably down. The read timeout is where you give the model room to think.
Model Fallback Chains
When your primary model is overloaded or down, falling back to a cheaper or faster model beats showing an error. EzAI makes this trivial since all models share the same endpoint — you just change the model string.
import anthropic
import logging
logger = logging.getLogger(__name__)
FALLBACK_CHAIN = [
"claude-opus-4-6", # Primary: best quality
"claude-sonnet-4-5", # Fallback 1: fast + capable
"gpt-4.1", # Fallback 2: cross-provider
"claude-haiku-3-5", # Fallback 3: cheap + fast
]
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
def call_with_fallback(messages, max_tokens=2048):
for model in FALLBACK_CHAIN:
try:
response = client.messages.create(
model=model,
max_tokens=max_tokens,
messages=messages,
)
if model != FALLBACK_CHAIN[0]:
logger.warning(f"Used fallback model: {model}")
return response
except (anthropic.RateLimitError, anthropic.APIStatusError) as e:
logger.error(f"{model} failed: {e}")
continue
raise RuntimeError("All models in fallback chain exhausted")Notice how you can mix providers in the chain — Claude, GPT, Gemini — all through the same EzAI endpoint. If Anthropic's infrastructure has issues, your app seamlessly falls through to OpenAI without changing API format or authentication.
For a deeper dive into model routing strategies, check out our guide on AI model routing.
Combining Retries with Fallbacks
The real production pattern combines both: retry the current model a couple of times, then fall back to the next one. Here's a battle-tested implementation:
import anthropic, random, time, logging
logger = logging.getLogger(__name__)
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
MODELS = ["claude-sonnet-4-5", "gpt-4.1", "claude-haiku-3-5"]
RETRIES_PER_MODEL = 2
def resilient_call(messages, max_tokens=2048):
for model in MODELS:
for attempt in range(RETRIES_PER_MODEL):
try:
resp = client.messages.create(
model=model,
max_tokens=max_tokens,
messages=messages,
)
logger.info(f"Success: {model} (attempt {attempt+1})")
return resp
except anthropic.RateLimitError:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"Rate limited on {model}, retry in {wait:.1f}s")
time.sleep(wait)
except anthropic.APIStatusError as e:
if e.status_code in (500, 502, 503, 529):
logger.warning(f"Server error {e.status_code} on {model}")
time.sleep(3)
else:
raise
logger.error(f"Exhausted retries for {model}, moving to next")
raise RuntimeError("All models and retries exhausted")With 3 models × 2 retries each, your app gets 6 chances to return a response before giving up. In practice, the second model almost always succeeds — total outage across all providers is extremely rare.
Handling Streaming Errors
Streaming adds a wrinkle: the connection opens successfully, tokens start flowing, and then the stream drops mid-response. You need to handle partial completions differently than connection failures.
def stream_with_recovery(messages, model="claude-sonnet-4-5"):
collected = ""
try:
with client.messages.stream(
model=model,
max_tokens=4096,
messages=messages,
) as stream:
for text in stream.text_stream:
collected += text
yield text
except Exception as e:
if len(collected) > 100:
# Got a partial response — salvage it
logger.warning(f"Stream died after {len(collected)} chars")
yield "\n\n[Response truncated due to connection error]"
else:
# Got almost nothing — retry entirely
logger.error(f"Stream failed early: {e}")
raiseThe threshold (100 chars in this example) is important. If you got 2,000 tokens of a thoughtful answer and the connection dropped, salvaging the partial response is better than throwing it away and retrying. Adjust the threshold based on your use case. For more on streaming patterns, see our streaming guide.
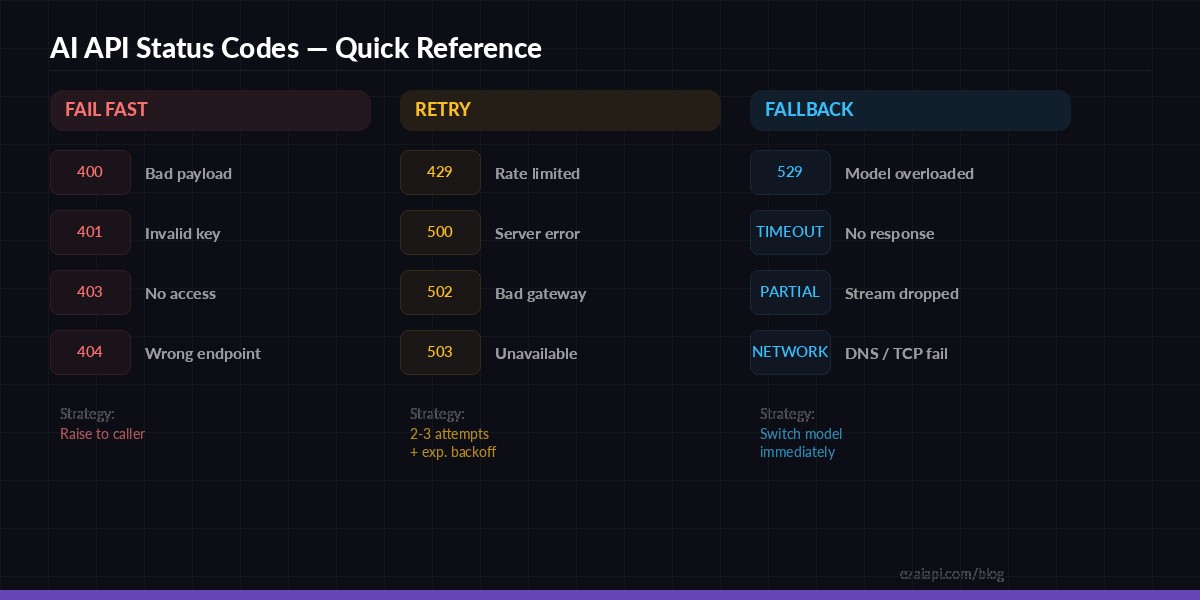
Quick reference — AI API status codes and the correct handling strategy for each
Circuit Breaker Pattern
If a model fails 5 times in a row, stop hammering it. The circuit breaker pattern tracks consecutive failures and temporarily removes a model from your rotation:
from dataclasses import dataclass, field
import time
@dataclass
class CircuitBreaker:
threshold: int = 5
cooldown: float = 60.0 # seconds before retry
failures: dict = field(default_factory=dict)
open_until: dict = field(default_factory=dict)
def is_available(self, model: str) -> bool:
if model in self.open_until:
if time.time() < self.open_until[model]:
return False
del self.open_until[model]
self.failures[model] = 0
return True
def record_failure(self, model: str):
self.failures[model] = self.failures.get(model, 0) + 1
if self.failures[model] >= self.threshold:
self.open_until[model] = time.time() + self.cooldown
def record_success(self, model: str):
self.failures[model] = 0
breaker = CircuitBreaker()
def smart_call(messages):
for model in MODELS:
if not breaker.is_available(model):
continue
try:
resp = client.messages.create(
model=model, max_tokens=2048, messages=messages,
)
breaker.record_success(model)
return resp
except Exception:
breaker.record_failure(model)
raise RuntimeError("No available models")After 5 consecutive failures, the circuit "opens" and that model is bypassed for 60 seconds. This prevents wasting time and money retrying a dead endpoint while your fallback models pick up the slack.
Practical Checklist for Production
Before deploying any AI-powered feature, run through this:
- Set explicit timeouts — never rely on defaults (they're usually too generous)
- Retry only retryable errors — 429, 500, 502, 503, 529. Never retry 400, 401, 403
- Add jitter to backoff —
random.uniform(0, base_delay * 0.5)prevents thundering herds - Configure a fallback chain — at least 2 models, ideally across providers
- Log every failure — model name, error code, attempt number, response time. You'll need this data
- Monitor p99 latency — if your p99 spikes, your timeout or retry logic needs tuning
- Test failure scenarios — inject fake 429s in staging. Your code should handle them without intervention
EzAI handles much of this complexity for you — built-in model fallback, automatic retry on provider errors, and intelligent routing across providers. But understanding these patterns means you can build a second layer of resilience in your own code, making your app virtually bulletproof.
Start building at ezaiapi.com — every new account gets 15 free credits to test these patterns with real API traffic.