
Your AI gateway hits 1,200 RPS during a launch. The upstream model can sustain 400. Without backpressure, the queue grows unbounded, p99 latency rockets to 90 seconds, healthchecks start failing, the load balancer panics, and you page on-call at 3 AM. With backpressure, slow callers see 429 Too Many Requests, fast callers degrade gracefully, and your dashboard stays green.
This post is about the boring plumbing that keeps AI APIs alive under load: rejecting requests early, bounding queues, and shaping traffic with token buckets. We'll use real code against ezaiapi.com, but every pattern works against any upstream provider.
Why AI APIs need backpressure more than most
Three things make LLM workloads brutal compared to a regular REST service:
- Per-request cost is huge. A single completion can take 30 seconds and consume 8K tokens. One stuck request occupies a worker for the duration of a small batch job.
- Latency variance is enormous. A 200-token prompt with a 100-token answer might take 800ms. The same prompt with a long answer can take 45 seconds. Capacity planning by averages lies to you.
- Upstream rate limits are strict and tiered. Anthropic, OpenAI, Google all enforce per-minute token and request limits. Cross them and you cascade failures into your own users.
If you don't push back at the edge, the queue absorbs all the pain — until it doesn't. You want to fail at the door, not in the middle of a 30-second stream.
The three patterns you actually need
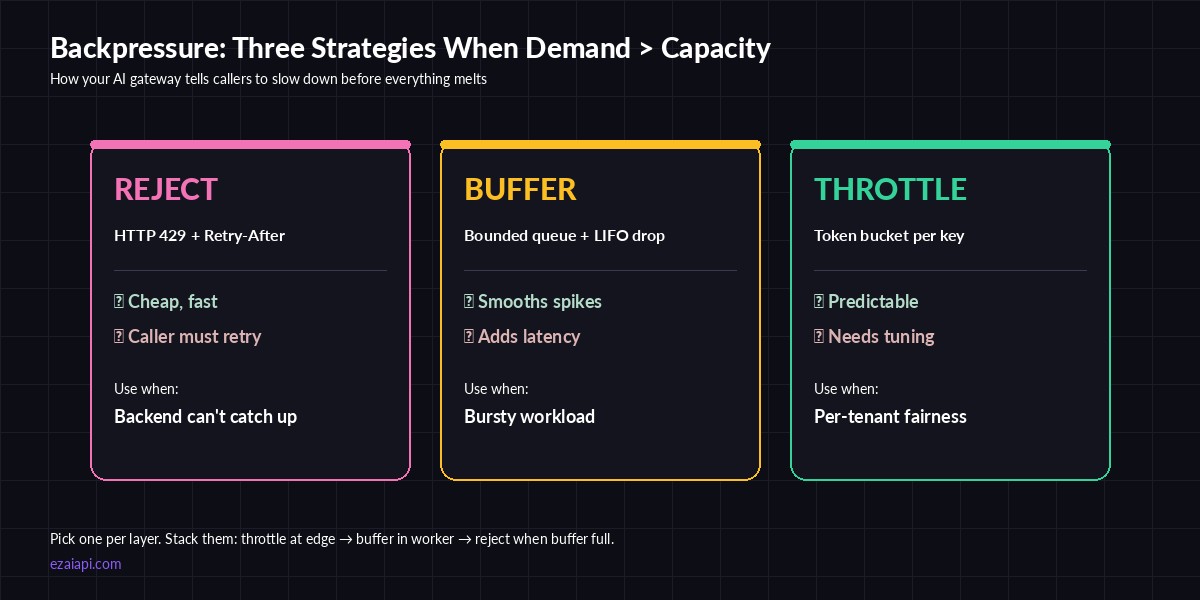
Reject, buffer, throttle — pick one per layer, stack them at the edges
The classic Reactive Streams playbook gives you four primitives: buffer, drop, throttle, and signal back. For AI gateways, the working set boils down to:
- Reject early with
429and aRetry-Afterheader when concurrency exceeds your capacity. - Bounded queue in the worker so spikes get smoothed but the queue can't grow forever.
- Token bucket per API key so noisy neighbors can't starve everyone else.
Stack them. Throttle at the edge, buffer in the worker, reject when the buffer is full. Now you have a system that degrades predictably instead of falling off a cliff.
Pattern 1: Reject early with 429 + Retry-After
The cheapest backpressure is the one that runs before you allocate anything. Track in-flight requests with an atomic counter. If it crosses a threshold, reject immediately. The caller sees a real HTTP status, not a 60-second timeout.
// gateway.js — concurrency limiter in front of EzAI
import express from "express";
import Anthropic from "@anthropic-ai/sdk";
const MAX_INFLIGHT = 200;
let inflight = 0;
const client = new Anthropic({
apiKey: process.env.EZAI_KEY,
baseURL: "https://ezaiapi.com",
});
const app = express();
app.use(express.json());
app.post("/chat", async (req, res) => {
if (inflight >= MAX_INFLIGHT) {
res.setHeader("Retry-After", "2");
return res.status(429).json({ error: "overloaded" });
}
inflight++;
try {
const msg = await client.messages.create({
model: "claude-sonnet-4-5",
max_tokens: 1024,
messages: req.body.messages,
});
res.json(msg);
} finally {
inflight--;
}
});
app.listen(8080);
Two things make this work in practice: pick MAX_INFLIGHT based on your actual upstream concurrency budget (usually 2–4× your steady-state throughput target), and always set Retry-After. Good clients respect it; bad clients hammer you regardless and you can rate-limit them at the LB.
Pattern 2: Bounded queue with timeout
Pure rejection is harsh on bursty traffic. A small bounded queue absorbs micro-spikes without letting load build up. The trick is the bound — and a per-item deadline so requests that have been waiting too long get rejected before they're even started.
# worker.py — bounded queue + per-item deadline
import asyncio, time, anthropic
QUEUE_MAX = 50
WORKERS = 8
ITEM_TTL = 5.0 # reject if waiting > 5s
q: asyncio.Queue = asyncio.Queue(maxsize=QUEUE_MAX)
client = anthropic.AsyncAnthropic(
api_key=os.environ["EZAI_KEY"],
base_url="https://ezaiapi.com",
)
async def enqueue(payload):
item = {"payload": payload, "enq": time.monotonic(),
"fut": asyncio.Future()}
try:
q.put_nowait(item)
except asyncio.QueueFull:
raise RuntimeError("overloaded")
return await item["fut"]
async def worker():
while True:
item = await q.get()
if time.monotonic() - item["enq"] > ITEM_TTL:
item["fut"].set_exception(TimeoutError("queue stale"))
continue
try:
msg = await client.messages.create(**item["payload"])
item["fut"].set_result(msg)
except Exception as e:
item["fut"].set_exception(e)
async def main():
for _ in range(WORKERS):
asyncio.create_task(worker())
The TTL check is what separates a queue that helps from a queue that hides problems. Without it, a 30-second backlog still gets processed even though the user has long since given up — wasting tokens, money, and worker time on responses nobody will read. Pair this with request deadlines end-to-end.
Pattern 3: Token bucket per API key
Concurrency limits protect the system. Token buckets protect tenants from each other. One client running a backfill at 800 RPS shouldn't starve the rest of your customers. Track tokens per key, refill at a steady rate, reject when empty.
import time
from collections import defaultdict
class TokenBucket:
def __init__(self, rate, burst):
self.rate = rate # tokens/sec
self.burst = burst # bucket size
self.tokens = burst
self.ts = time.monotonic()
def take(self, n=1):
now = time.monotonic()
self.tokens = min(self.burst,
self.tokens + (now - self.ts) * self.rate)
self.ts = now
if self.tokens >= n:
self.tokens -= n
return True
return False
buckets = defaultdict(lambda: TokenBucket(rate=10, burst=30))
def allow(api_key, cost=1):
return buckets[api_key].take(cost)
Two upgrades worth doing once you've shipped this:
- Cost-weighted tokens. Take more tokens for expensive models or long
max_tokens. A request toclaude-opus-4with 8K output costs you 30× a Haiku call — your bucket should reflect that. - Move state to Redis. The in-process version above is fine for one node. With multiple gateway replicas, use a Lua script on Redis to make the take-and-decrement atomic.
Surfacing backpressure to clients
Backpressure only works if callers react. Three things make that easy:
- Standard status codes. Use
429for rate limit and503for "overloaded, try later". Don't invent418or wrap errors in 200s. - Honest
Retry-After. A real number (Retry-After: 3) lets smart retry logic back off without guesswork. - Expose limit headers. Mirror the upstream pattern:
X-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Reset. SDKs that already understand Anthropic's headers will Just Work.
What to monitor
You can't tune what you can't see. The four metrics that matter:
- Queue depth (gauge). If it sits non-zero, your steady-state capacity is too low.
- Reject rate (counter). By reason:
429_concurrency,429_token_bucket,queue_full,queue_stale. - Wait time histogram. Time from enqueue to worker pickup. p99 should be under your TTL.
- Inflight gauge. Should bounce around
MAX_INFLIGHT * 0.7— not pinned at the cap.
If you're already shipping OpenTelemetry traces, add a span attribute for backpressure decisions. When something goes sideways at 2 AM, you want to immediately see whether the gateway shed load or upstream hung.
Putting it together
The recipe that has worked across half a dozen production AI gateways:
- Token bucket per API key at the edge — fairness.
- Concurrency limit per gateway node — protection.
- Bounded queue per worker pool with TTL — burst absorption.
- Standard
429/503withRetry-After— graceful degradation. - Metrics on queue depth, wait time, reject reasons — observability.
Pair backpressure with circuit breakers on the upstream side and you have a gateway that bends instead of breaks. Try it against EzAI's unified endpoint at ezaiapi.com — you get one API key, predictable rate limits, and the ability to fail over between providers when one of them starts shedding load on you.