
Every time a new model drops — Claude 4.5 Opus, GPT‑5.1, Gemini 3 — you face the same question: will it actually behave well on my traffic? Benchmarks lie. Your own eval set is usually too small. And A/B tests put real users on the line. Shadow traffic testing solves all three problems by duplicating live requests to the candidate model without ever showing users the shadow output.
This post walks through a production-ready shadow testing pattern in Python using EzAI, including fan-out, async comparison, and the metrics that actually matter when promoting a model.
Why shadow traffic beats A/B testing
A/B tests are cheap to set up but expensive to run safely. Half your users see the unproven model. If the new model regresses on a rare prompt shape, real people see bad output. Shadow testing flips the tradeoff:
- Zero user exposure. Shadow responses are logged, diffed, and discarded. The user always gets the primary model's output.
- Real production distribution. Unlike an eval set, shadow traffic includes every weird prompt your users actually send — the long ones, the typos, the edge cases.
- Runs indefinitely. Keep it on for a week, capture tail behavior, then promote with confidence.
- Cheap with prompt caching. Shadowing doubles token usage on the candidate model only. Paired with prompt caching, cost stays sane.
The downside: shadow testing measures model behavior, not user preference. Once shadow metrics look clean, follow up with a canary rollout to get the human signal.
Shadow testing architecture
The flow has three pieces: a fan-out wrapper around your primary call, a fire-and-forget shadow call, and an async comparator that logs the diff. The primary response returns to the user on the normal hot path — shadow work never blocks it.
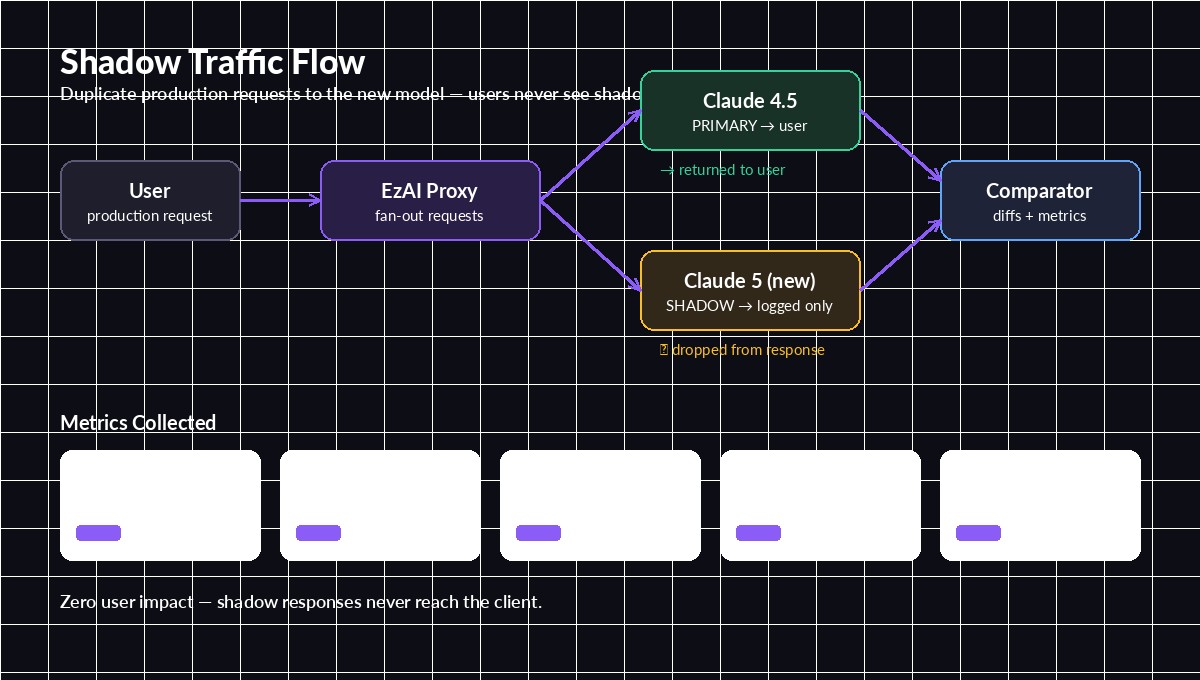
Primary serves the user; shadow runs in parallel and feeds the comparator
A few rules keep this safe:
- Never await the shadow call in the user-facing path. Use
asyncio.create_taskand let it complete independently. - Budget the shadow rate. Sample 5–20% of traffic, not 100%, unless you've confirmed the candidate model can handle your RPS.
- Cap shadow timeouts aggressively. A stuck shadow call should never delay logging or hold resources.
- Tag requests. Same
request_idon both calls so the comparator can join them.
Implementation with EzAI
EzAI makes shadow testing trivial because both models sit behind the same base URL and API key. No second credential to manage, no second billing line. Here's a minimal async wrapper:
import asyncio, uuid, time, json, logging
from anthropic import AsyncAnthropic
client = AsyncAnthropic(
api_key="sk-your-ezai-key",
base_url="https://ezaiapi.com",
)
PRIMARY = "claude-sonnet-4-5"
SHADOW = "claude-opus-4-5"
SHADOW_RATE = 0.15 # 15% sampling
SHADOW_TIMEOUT = 30.0
async def call_with_shadow(messages, **kwargs):
req_id = str(uuid.uuid4())
t0 = time.monotonic()
primary = await client.messages.create(
model=PRIMARY, messages=messages, **kwargs,
)
primary_latency = time.monotonic() - t0
if __import__("random").random() < SHADOW_RATE:
asyncio.create_task(
_run_shadow(req_id, messages, kwargs, primary, primary_latency)
)
return primaryThe create_task call is the key line — Python launches the shadow coroutine and immediately returns. The user never waits. Here's the shadow side:
async def _run_shadow(req_id, messages, kwargs, primary, primary_latency):
t0 = time.monotonic()
try:
shadow = await asyncio.wait_for(
client.messages.create(model=SHADOW, messages=messages, **kwargs),
timeout=SHADOW_TIMEOUT,
)
shadow_latency = time.monotonic() - t0
log_comparison(req_id, primary, shadow, primary_latency, shadow_latency)
except asyncio.TimeoutError:
logging.warning("shadow_timeout", extra={"req_id": req_id})
except Exception as e:
logging.warning("shadow_error", extra={"req_id": req_id, "err": str(e)})Notice the exception handler catches everything. A broken shadow model must never affect production. Log it, move on.
Comparing responses safely
Raw string equality is useless — two good responses almost never match word-for-word. The metrics that actually tell you something:
- Latency delta (p50, p95, p99). Is the new model slower at the tail?
- Token usage delta. Does it write longer answers for the same prompt? That's real money.
- Semantic similarity. Embed both outputs with a small model, cosine-compare. Flag anything below ~0.85.
- Refusal / hedge rate. Regex for "I can't", "as an AI", "I'm unable" — new models sometimes get more cautious.
- Tool-call match. If you use function calling, did both models pick the same tool with the same arguments?
A simple comparator that logs structured JSON for your observability pipeline:
def log_comparison(req_id, primary, shadow, p_lat, s_lat):
p_text = primary.content[0].text
s_text = shadow.content[0].text
record = {
"req_id": req_id,
"primary_model": primary.model,
"shadow_model": shadow.model,
"latency_delta_ms": round((s_lat - p_lat) * 1000, 1),
"tokens_in_delta": shadow.usage.input_tokens - primary.usage.input_tokens,
"tokens_out_delta": shadow.usage.output_tokens - primary.usage.output_tokens,
"primary_len": len(p_text),
"shadow_len": len(s_text),
"similarity": cosine_sim(p_text, s_text),
"primary_refused": looks_like_refusal(p_text),
"shadow_refused": looks_like_refusal(s_text),
}
logging.info("shadow_compare", extra=record)Ship those records to ClickHouse, BigQuery, or even a flat JSONL file. After a few million rows you'll have clear percentile curves for every metric, grouped by prompt type. That's your decision-quality data.
When to promote the candidate model
Don't trust averages — always look at tails. A model can have better p50 latency and still be worse at p99, which is what users actually feel. Concrete promotion criteria that have worked for us:
- p95 latency delta ≤ +10% vs primary
- Output tokens per request delta ≤ +15% (cost sanity)
- Semantic similarity ≥ 0.85 on >95% of paired requests
- No net-new refusals on previously-successful prompts
- Zero error-rate increase on tool-calling paths
If the candidate clears all five over a full week of shadow traffic, you've earned the right to move to a canary rollout. Start at 1%, ramp to 10%, then 50%, then flip the default. If anything looks off at canary, you already have shadow baselines to diff against.
Wrap-up
Shadow traffic is the cheapest insurance you can buy before a model upgrade. You get real production behavior, zero user risk, and a hard data trail that turns "I think it's fine" into "here are the numbers." Pair it with prompt regression tests on your critical prompts, and you'll never ship a model blind again.
Everything in this post runs against a single EzAI endpoint — grab a key, flip your base URL, and you can start shadowing tonight. For deeper reading on production rollout patterns, Martin Fowler's Parallel Change note is still the best one-page primer on this whole shape of deploy.