
Your Downloads folder has 2,000 files. Invoices mixed with memes, screenshots tangled with source code, and PDFs from three years ago buried under vacation photos. You could spend a Saturday sorting them manually, or you could let Claude do it in under a minute. In this tutorial, we'll build a Python CLI that reads filenames and content, sends them to Claude for intelligent classification, and moves each file into the right folder automatically.
What We're Building
The finished tool does three things: scans a target directory for unorganized files, sends batches of filenames to Claude for categorization, and moves each file into a labeled subfolder. It handles duplicates, respects dry-run mode so you can preview changes before committing, and processes hundreds of files in a single API call by batching filenames together.
The entire script is around 120 lines of Python. No ML training, no custom classifiers — just a well-crafted prompt and structured JSON output from Claude.
Prerequisites
You'll need Python 3.10+, an EzAI API key, and the Anthropic SDK:
pip install anthropicSet your EzAI credentials as environment variables:
export ANTHROPIC_API_KEY="sk-your-ezai-key"
export ANTHROPIC_BASE_URL="https://ezaiapi.com"The Classification Prompt
The prompt is the brain of the whole operation. We send Claude a list of filenames and ask it to return a JSON array mapping each file to a category. The key trick: we let Claude infer categories from the actual files rather than forcing a fixed list. This means the tool adapts to any directory — a developer's project folder gets categories like source-code, configs, and docs, while a photographer's folder gets raw-photos, edits, and exports.
SYSTEM_PROMPT = """You are a file organization assistant. Given a list of filenames,
classify each into a logical folder category.
Rules:
- Use lowercase kebab-case for category names (e.g. "source-code", "invoices")
- Create 5-12 categories max — group similar files together
- Common categories: documents, images, screenshots, source-code,
configs, archives, videos, music, spreadsheets, presentations, misc
- If a file doesn't fit anywhere obvious, use "misc"
- Return ONLY valid JSON, no markdown fences
Output format:
[{"file": "example.py", "category": "source-code"}, ...]"""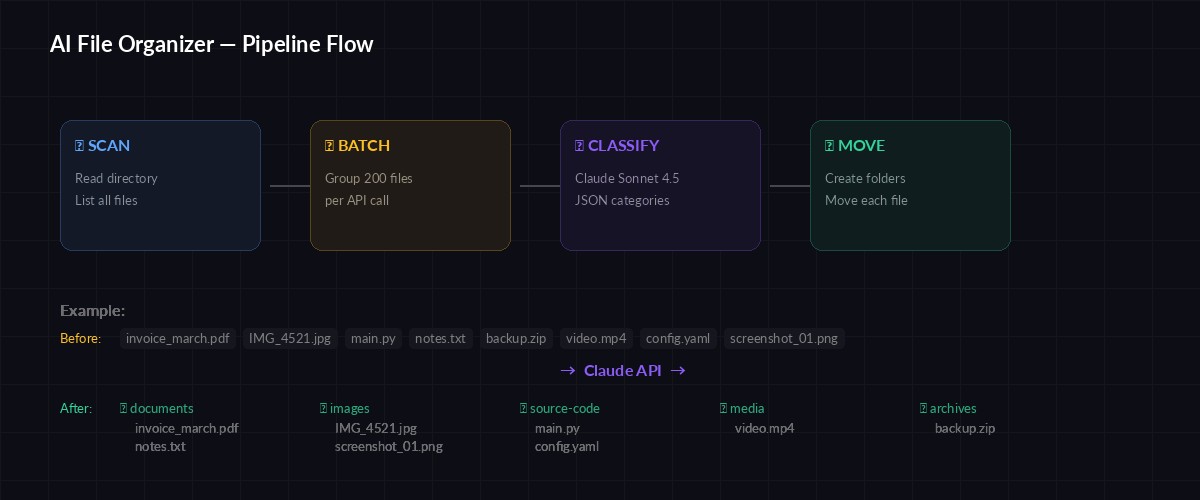
The pipeline: scan files → batch filenames → Claude classifies → move to folders
Building the Organizer
Here's the complete script. It scans the target directory, batches filenames into groups of 200 (to stay within token limits), sends each batch to Claude, and moves files based on the response:
import os, json, shutil, argparse
from pathlib import Path
import anthropic
client = anthropic.Anthropic(
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://ezaiapi.com")
)
BATCH_SIZE = 200 # filenames per API call
def scan_files(directory: Path) -> list[str]:
"""Get all files in directory (not subdirs)."""
return [
f.name for f in directory.iterdir()
if f.is_file() and not f.name.startswith(".")
]
def classify_batch(filenames: list[str]) -> list[dict]:
"""Send a batch of filenames to Claude for classification."""
file_list = "\n".join(filenames)
message = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=[{
"role": "user",
"content": f"Classify these files:\n{file_list}"
}]
)
raw = message.content[0].text.strip()
return json.loads(raw)
def move_file(src: Path, dest_dir: Path, dry_run: bool) -> str:
"""Move file to destination, handling duplicates."""
dest_dir.mkdir(parents=True, exist_ok=True)
dest = dest_dir / src.name
# Handle duplicate filenames
if dest.exists():
stem, suffix = src.stem, src.suffix
counter = 1
while dest.exists():
dest = dest_dir / f"{stem}_{counter}{suffix}"
counter += 1
if dry_run:
return f"[DRY RUN] {src.name} → {dest_dir.name}/"
shutil.move(str(src), str(dest))
return f"✓ {src.name} → {dest_dir.name}/"
def organize(directory: str, dry_run: bool = False):
target = Path(directory).resolve()
files = scan_files(target)
if not files:
print("No files found to organize.")
return
print(f"Found {len(files)} files. Classifying...")
# Process in batches
all_mappings = []
for i in range(0, len(files), BATCH_SIZE):
batch = files[i:i + BATCH_SIZE]
print(f" Batch {i // BATCH_SIZE + 1}: {len(batch)} files")
mappings = classify_batch(batch)
all_mappings.extend(mappings)
# Move files
categories = {}
for item in all_mappings:
src = target / item["file"]
if not src.exists():
continue
cat = item["category"]
dest_dir = target / cat
result = move_file(src, dest_dir, dry_run)
print(f" {result}")
categories[cat] = categories.get(cat, 0) + 1
print(f"\nOrganized into {len(categories)} categories:")
for cat, count in sorted(categories.items()):
print(f" 📁 {cat}: {count} files")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="AI-powered file organizer")
parser.add_argument("directory", help="Path to organize")
parser.add_argument("--dry-run", action="store_true",
help="Preview changes without moving files")
args = parser.parse_args()
organize(args.directory, args.dry_run)Run it with --dry-run first to preview the results:
python organize.py ~/Downloads --dry-run
# Output:
# Found 847 files. Classifying...
# Batch 1: 200 files
# Batch 2: 200 files
# Batch 3: 200 files
# Batch 4: 200 files
# Batch 5: 47 files
# [DRY RUN] invoice_2025_03.pdf → invoices/
# [DRY RUN] IMG_4521.jpg → images/
# [DRY RUN] main.py → source-code/
# ...
# Organized into 9 categories:
# 📁 archives: 23 files
# 📁 documents: 156 files
# 📁 images: 312 files
# 📁 source-code: 89 filesAdding Content-Aware Classification
Filename-based classification works for 90% of files. But what about report.pdf — is that a financial report, a bug report, or a school assignment? For ambiguous files, we can peek at the content. Here's an enhanced version that reads the first 500 bytes of text-based files:
TEXT_EXTENSIONS = {".txt", ".md", ".py", ".js", ".ts", ".json", ".csv", ".log"}
def get_file_context(filepath: Path) -> str:
"""Read first 500 bytes of text files for better classification."""
if filepath.suffix.lower() not in TEXT_EXTENSIONS:
return ""
try:
with open(filepath, "r", errors="ignore") as f:
preview = f.read(500)
return f" [preview: {preview[:200]}]"
except:
return ""
def classify_batch_with_context(directory: Path, filenames: list[str]) -> list[dict]:
"""Classify files with optional content previews."""
entries = []
for name in filenames:
ctx = get_file_context(directory / name)
entries.append(f"{name}{ctx}")
message = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=[{
"role": "user",
"content": "Classify these files:\n" + "\n".join(entries)
}]
)
return json.loads(message.content[0].text.strip())Content-aware mode uses slightly more tokens per batch, but the classification accuracy jumps dramatically. A file named notes.txt containing meeting minutes gets sorted into meetings instead of the generic documents folder.
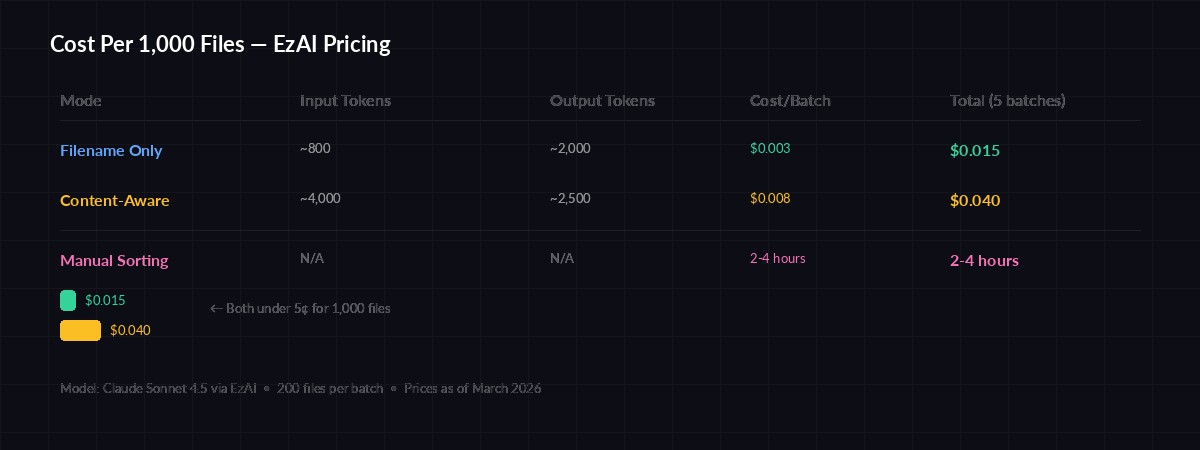
Cost per 1,000 files: filename-only ~$0.003 vs content-aware ~$0.02 via EzAI
Handling Edge Cases
Real-world directories are messy. Here are the edge cases the script handles:
- Duplicate filenames — if
images/photo.jpgalready exists, the file becomesimages/photo_1.jpg - Hidden files — anything starting with
.is skipped (your.gitignorestays put) - Empty directories — the script exits gracefully with a message
- Huge directories — batching at 200 files keeps each API call under 8K tokens
- JSON parse failures — wrap the parse in a try/except and retry once with a stricter prompt
One thing the script intentionally does not do: it won't recurse into subdirectories. If you've already organized some files into folders, those folders stay untouched. Only loose files in the top-level directory get classified.
Cost Breakdown
Using Claude Sonnet 4.5 through EzAI's pricing, the cost is remarkably low:
- 200 filenames ≈ 800 input tokens + 2,000 output tokens = ~$0.003 per batch
- 1,000 files = 5 batches ≈ $0.015 total
- Content-aware mode adds ~2x token usage, still under $0.04 for 1,000 files
For comparison, manually organizing 1,000 files takes 2-4 hours. The AI version takes 15 seconds and costs less than a penny through EzAI. If you need even lower costs, swap claude-sonnet-4-5 for a free model — filename-only classification works well on smaller models too.
Extending the Tool
The base script is deliberately minimal. Here are practical extensions you can add:
- Undo support — log every move to a JSON file, then add an
--undoflag that reverses all operations - Custom rules — pass a
--rulesflag with domain-specific categories ("put all .blend files in 3d-projects") - Watch mode — use
watchdogto monitor a folder and auto-organize new files as they arrive - Date-based sorting — combine AI categories with file modification dates for time-bucketed folders like
invoices/2026-Q1/
The pattern here scales to any classification task. Swap filenames for email subjects, support tickets, or customer feedback — the approach is identical. Send text to Claude, get structured categories back, act on the result.
Wrapping Up
You now have a working AI file organizer that classifies hundreds of files in seconds. The cost is negligible through EzAI, the accuracy is surprisingly good (even with filename-only mode), and the dry-run flag means zero risk of accidental data loss.
Grab an EzAI API key, copy the script, and point it at your messiest folder. Then check our guides on structured JSON output and batch API requests for more patterns like this.