
Every team has a deployment horror story. A config change that took down prod for three hours. A migration that silently dropped a column. A dependency bump that broke auth. Most of these incidents share one trait: a human glanced at the diff, said "looks fine," and hit merge.
What if your CI pipeline could read the diff, understand the context, score the risk, and either approve, flag, or block the deploy — all before a human even looks at it? That's what we're building today: an AI deployment gatekeeper that plugs into any CI/CD system using Python and the Claude API via EzAI.
How the Pipeline Works
The system sits between your merge event and the actual deployment. When a PR merges into main, it collects the git diff, recent commit messages, and any changed config files. It sends all of that to Claude with a structured prompt, and gets back a JSON response containing a risk score, a plain-English summary, and a deploy/hold/block recommendation.
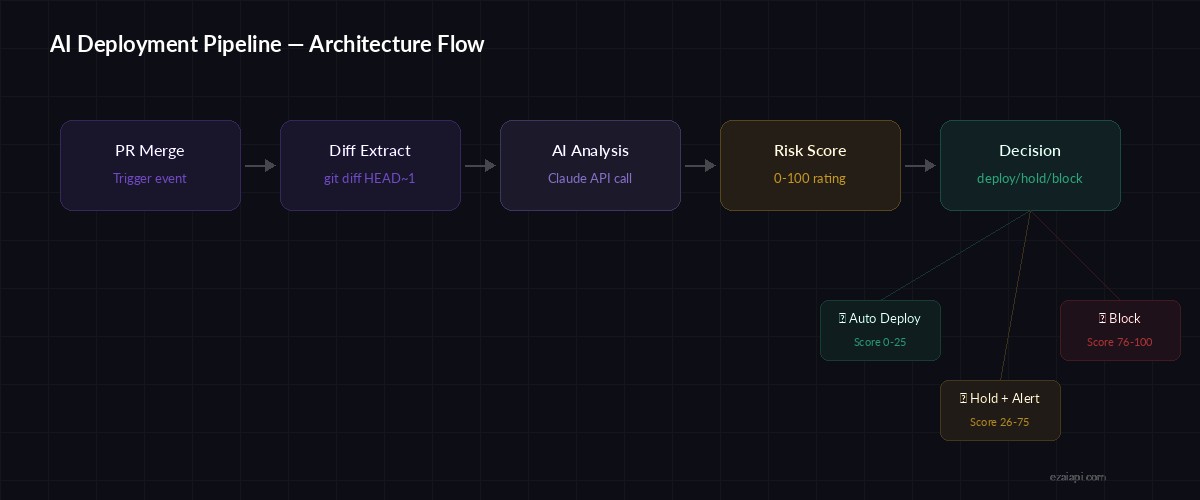
Pipeline flow: PR merge → diff extraction → AI analysis → deploy decision
The risk scoring isn't binary. It returns a number from 0 to 100 with category breakdowns — schema changes, auth modifications, dependency updates, config drift — so you know exactly why a deploy got flagged.
Setting Up the Client
Install the Anthropic SDK and set up the EzAI-routed client. We'll use EzAI's proxy to keep costs low — deployment analysis runs on every merge, so token spend adds up fast.
pip install anthropic gitpythonimport anthropic
import json
import subprocess
client = anthropic.Anthropic(
api_key="sk-your-ezai-key",
base_url="https://ezaiapi.com"
)Extracting the Diff
The first step is grabbing the actual changes. We pull the diff between the current commit and its parent, along with the last 10 commit messages for context. The diff gets truncated at 12,000 characters to stay within reasonable token limits — if a PR is larger than that, it probably should've been split anyway.
def get_deploy_context(repo_path: str, max_diff_chars: int = 12000) -> dict:
"""Extract diff and recent commits from the repo."""
diff = subprocess.run(
["git", "diff", "HEAD~1", "HEAD"],
cwd=repo_path, capture_output=True, text=True
).stdout[:max_diff_chars]
commits = subprocess.run(
["git", "log", "--oneline", "-10"],
cwd=repo_path, capture_output=True, text=True
).stdout.strip()
changed_files = subprocess.run(
["git", "diff", "--name-only", "HEAD~1", "HEAD"],
cwd=repo_path, capture_output=True, text=True
).stdout.strip().split("\n")
return {
"diff": diff,
"commits": commits,
"changed_files": changed_files,
"file_count": len(changed_files)
}The Risk Analysis Prompt
The prompt is where the real work happens. We give Claude a specific role (senior SRE doing a deploy review), feed it the diff and commit context, and ask for structured JSON output. The categories map to the things that actually cause outages — not theoretical risks, but the patterns that have burned teams in production.
REVIEW_PROMPT = """You are a senior SRE reviewing a deployment.
Analyze this diff and return a JSON object with:
{
"risk_score": 0-100,
"recommendation": "deploy" | "hold" | "block",
"summary": "one paragraph explaining the changes",
"risks": [
{"category": "schema|auth|deps|config|data|infra",
"severity": "low|medium|high|critical",
"detail": "what specifically could go wrong"}
],
"rollback_notes": "what to watch and how to revert"
}
Risk scoring guide:
- 0-25: Cosmetic, docs, tests — safe to auto-deploy
- 26-50: Feature code, new endpoints — standard review
- 51-75: DB migrations, auth changes, config — needs human approval
- 76-100: Breaking changes, data migrations, infra — block and discuss
Changed files: {changed_files}
Recent commits: {commits}
Diff:
{diff}
Return ONLY valid JSON. No markdown, no explanation outside the JSON."""
def analyze_deploy(context: dict) -> dict:
prompt = REVIEW_PROMPT.format(
changed_files=", ".join(context["changed_files"]),
commits=context["commits"],
diff=context["diff"]
)
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1500,
messages=[{"role": "user", "content": prompt}]
)
return json.loads(response.content[0].text)Wiring It Into CI
The gatekeeper script runs as a CI step after merge. It exits with code 0 (deploy), 1 (block), or prints a warning for holds. Here's the full runner that you'd call from GitHub Actions, GitLab CI, or any shell-based pipeline:

Risk categories and their impact on deploy decisions
import sys
import os
def run_deploy_gate():
repo_path = os.environ.get("GITHUB_WORKSPACE", ".")
context = get_deploy_context(repo_path)
print(f"📋 Analyzing {context['file_count']} changed files...")
result = analyze_deploy(context)
score = result["risk_score"]
rec = result["recommendation"]
print(f"\n{'='*50}")
print(f"Risk Score: {score}/100")
print(f"Recommendation: {rec.upper()}")
print(f"Summary: {result['summary']}")
if result["risks"]:
print(f"\n⚠️ Risks found:")
for risk in result["risks"]:
icon = {"critical": "🔴", "high": "🟠",
"medium": "🟡", "low": "🟢"}
print(f" {icon.get(risk['severity'], '⚪')} [{risk['category']}] {risk['detail']}")
print(f"\n🔄 Rollback: {result['rollback_notes']}")
if rec == "block":
print("\n🚫 DEPLOY BLOCKED — manual review required")
sys.exit(1)
elif rec == "hold":
print("\n⏸️ DEPLOY ON HOLD — flagged for review")
# Exit 0 but post a Slack/Discord alert
else:
print("\n✅ DEPLOY APPROVED — proceeding")
if __name__ == "__main__":
run_deploy_gate()GitHub Actions Integration
Drop this into your workflow YAML. The AI gate runs after tests pass and before the actual deploy step. If it exits non-zero, the deploy halts automatically.
name: Deploy with AI Gate
on:
push:
branches: [main]
jobs:
ai-gate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 2 # Need parent commit for diff
- uses: actions/setup-python@v5
with:
python-version: "3.12"
- run: pip install anthropic
- run: python scripts/deploy_gate.py
env:
ANTHROPIC_API_KEY: ${{ secrets.EZAI_API_KEY }}
deploy:
needs: ai-gate
runs-on: ubuntu-latest
steps:
- run: echo "Deploying to production..."Adding Slack Notifications
A blocked deploy is useless if nobody sees it. Bolt on a Slack webhook to post the analysis to your team's deploy channel whenever a risk score exceeds your threshold.
import urllib.request
def notify_slack(result: dict, webhook_url: str):
score = result["risk_score"]
emoji = "🚫" if score > 75 else "⚠️" if score > 50 else "✅"
risks_text = "\n".join(
f"• [{r['severity'].upper()}] {r['detail']}"
for r in result["risks"]
)
payload = json.dumps({"text":
f"{emoji} *Deploy Gate — Score: {score}/100*\n"
f"Rec: {result['recommendation'].upper()}\n\n"
f"{result['summary']}\n\n"
f"*Risks:*\n{risks_text}\n\n"
f"_Rollback: {result['rollback_notes']}_"
})
req = urllib.request.Request(
webhook_url, data=payload.encode(),
headers={"Content-Type": "application/json"}
)
urllib.request.urlopen(req)Cost Breakdown
Running this on every merge is cheaper than you'd think. A typical diff analysis uses about 3,000-5,000 input tokens and generates around 500 output tokens. With EzAI's pricing on Claude Sonnet, that's roughly $0.01-0.02 per deploy. Even at 50 deploys per day, you're spending less than a dollar — far less than one engineer hour spent debugging a bad deploy.
To squeeze costs further, use prompt caching for the system prompt. The review instructions stay the same across deploys, so only the diff and commit context count as new tokens. This cuts input costs by about 80% on repeated runs.
Beyond the Basics
Once the core pipeline is working, there are a few high-value extensions worth building:
- Historical calibration — Feed past incident post-mortems into the prompt so the model learns your team's specific failure patterns
- Auto-generated rollback scripts — Ask Claude to generate the exact revert commands based on the diff
- Canary analysis — After deploy, send error rate metrics back to Claude for real-time anomaly detection
- Multi-model consensus — Run the same diff through multiple models and require agreement before auto-deploying
The goal isn't to remove humans from the loop. It's to make sure the human review happens where it matters — on the deploys that actually carry risk — instead of rubber-stamping every CSS tweak and README update.
Grab your EzAI API key and try it on your next merge. You'll catch things that pass code review but fail common sense.