
Your AI model returned {"price": -42.99}. Your frontend displayed it. A customer saw a negative price and filed a support ticket. The fix took three minutes — but the trust took weeks to rebuild. AI output guardrails prevent exactly this class of failure by catching bad responses before they reach users.
Every production AI system needs a validation layer between the model and the user. Models hallucinate, return malformed JSON, inject unintended content, and occasionally produce outputs that are structurally correct but semantically wrong. Guardrails are the safety net that catches all of it.
The Guardrail Pipeline Architecture
A well-designed guardrail system sits between the AI response and your application logic. It runs a chain of validators — each one checking a different aspect of the output. If any validator fails, the system either retries the request, falls back to a default, or returns a safe error.
Here's the core pipeline structure using EzAI's API:
import anthropic
import json
from dataclasses import dataclass
from typing import Any, Callable
@dataclass
class GuardrailResult:
passed: bool
value: Any = None
error: str = ""
class OutputGuardrail:
def __init__(self):
self.validators: list[Callable] = []
self.client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com"
)
def add_validator(self, fn: Callable):
self.validators.append(fn)
return self
def validate(self, raw_output: str) -> GuardrailResult:
current = raw_output
for validator in self.validators:
result = validator(current)
if not result.passed:
return result
current = result.value if result.value else current
return GuardrailResult(passed=True, value=current)This is the skeleton. Every validator returns a GuardrailResult — either pass (with an optionally transformed value) or fail (with an error message). The pipeline short-circuits on the first failure. Now let's build the actual validators.
Schema Validation: Catching Malformed JSON
The most common failure mode is the model returning invalid JSON or JSON that doesn't match your expected schema. Maybe it adds extra fields, nests things differently, or returns a string where you expected an integer. A schema validator catches this immediately.
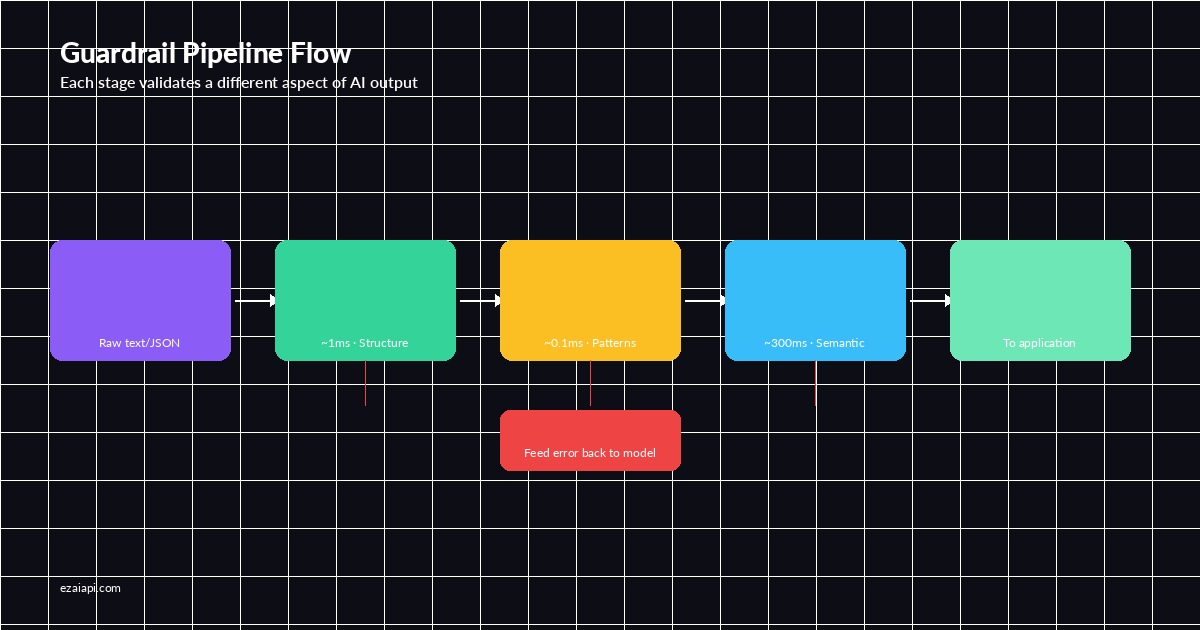
The guardrail pipeline: each stage validates a different aspect of the AI output
from jsonschema import validate, ValidationError
def schema_validator(schema: dict) -> Callable:
def _validate(raw: str) -> GuardrailResult:
# Strip markdown code fences if present
text = raw.strip()
if text.startswith("```"):
text = "\n".join(text.split("\n")[1:-1])
try:
parsed = json.loads(text)
validate(instance=parsed, schema=schema)
return GuardrailResult(passed=True, value=parsed)
except json.JSONDecodeError as e:
return GuardrailResult(passed=False, error=f"Invalid JSON: {e}")
except ValidationError as e:
return GuardrailResult(passed=False, error=f"Schema mismatch: {e.message}")
return _validate
# Define your expected output schema
product_schema = {
"type": "object",
"required": ["name", "price", "category"],
"properties": {
"name": {"type": "string", "minLength": 1},
"price": {"type": "number", "minimum": 0},
"category": {"type": "string", "enum": ["electronics", "clothing", "food"]}
},
"additionalProperties": False
}Notice the code fence stripping — models frequently wrap JSON in ```json ... ``` blocks even when you ask them not to. A production guardrail handles this gracefully rather than failing on perfectly valid data wrapped in markdown.
Content Filtering: Blocking Toxic or Unsafe Output
Schema validation ensures the response is structurally correct. Content filtering ensures it's semantically safe. This covers PII leakage, toxic language, prompt injection echoes, and outputs that violate your application's content policy.
The most reliable approach is a two-layer filter: a fast regex-based check for known patterns, followed by an AI-powered classification for nuanced cases.
import re
# Layer 1: Fast regex patterns for known bad outputs
BLOCKED_PATTERNS = [
re.compile(r'\b\d{3}-\d{2}-\d{4}\b'), # SSN
re.compile(r'\b\d{16}\b'), # Credit card
re.compile(r'(?i)ignore\s+(previous|all)\s+instructions'), # Injection echo
re.compile(r'(?i)system\s*prompt'), # Prompt leak
]
def regex_content_filter(text: str) -> GuardrailResult:
content = text if isinstance(text, str) else json.dumps(text)
for pattern in BLOCKED_PATTERNS:
match = pattern.search(content)
if match:
return GuardrailResult(
passed=False,
error=f"Blocked pattern detected: {pattern.pattern}"
)
return GuardrailResult(passed=True, value=text)
# Layer 2: AI-powered content classification
def ai_content_classifier(guardrail: OutputGuardrail) -> Callable:
def _classify(text: str) -> GuardrailResult:
content = text if isinstance(text, str) else json.dumps(text)
msg = guardrail.client.messages.create(
model="claude-haiku-3", # Fast + cheap for classification
max_tokens=20,
messages=[{"role": "user", "content": f"""Classify this AI output as SAFE or UNSAFE.
UNSAFE = contains PII, harmful instructions, or policy violations.
Output only: SAFE or UNSAFE
Text: {content[:500]}"""}]
)
verdict = msg.content[0].text.strip().upper()
if "UNSAFE" in verdict:
return GuardrailResult(passed=False, error="Content flagged as unsafe")
return GuardrailResult(passed=True, value=text)
return _classifyThe regex layer runs in microseconds and catches obvious patterns. The AI classifier costs fractions of a cent per call using Haiku through EzAI and handles edge cases that regex can't. Run the fast check first — you'll only hit the AI classifier on outputs that pass the regex screen.
Retry Logic with Automatic Recovery
When a guardrail check fails, you have three options: retry with the same prompt, retry with a corrective prompt that includes the error, or fall back to a default value. The best approach combines all three in a tiered strategy.
import time
def guarded_completion(
guardrail: OutputGuardrail,
messages: list,
model: str = "claude-sonnet-4-5",
max_retries: int = 3,
fallback: Any = None
) -> dict:
last_error = ""
for attempt in range(max_retries):
# On retry, append the error as corrective feedback
retry_messages = messages.copy()
if last_error and attempt > 0:
retry_messages.append({
"role": "user",
"content": f"Your previous output failed validation: {last_error}. Fix it and try again. Return ONLY valid JSON."
})
response = guardrail.client.messages.create(
model=model,
max_tokens=2048,
messages=retry_messages
)
raw = response.content[0].text
result = guardrail.validate(raw)
if result.passed:
return {
"data": result.value,
"attempts": attempt + 1,
"model": model
}
last_error = result.error
time.sleep(0.5 * (attempt + 1)) # Linear backoff
# All retries exhausted
if fallback is not None:
return {"data": fallback, "attempts": max_retries, "fallback": True}
raise ValueError(f"Guardrail failed after {max_retries} attempts: {last_error}")The corrective retry is the key insight here. Instead of blindly retrying the same prompt, you feed the validation error back to the model. Claude is remarkably good at self-correcting when you tell it exactly what went wrong. Most schema failures resolve on the first corrective retry.
Putting It All Together
Here's the complete guardrail pipeline wired up end-to-end. This example validates a product extraction task — the model reads a product description and returns structured data.
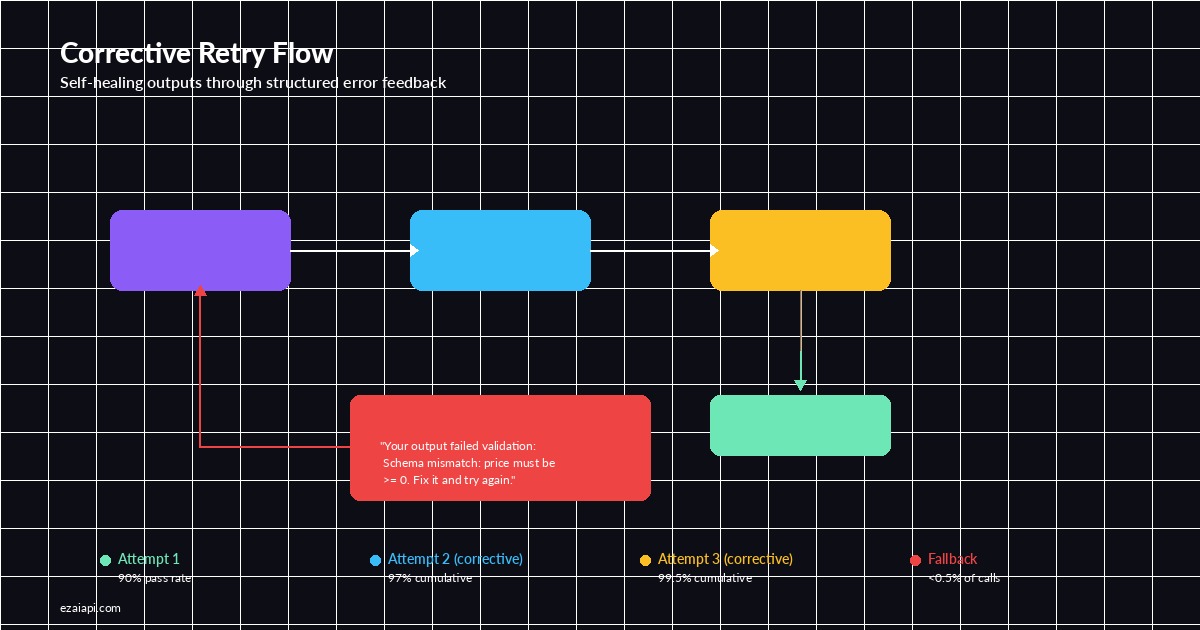
Corrective retry: feed validation errors back to the model for self-healing outputs
# Wire up the full pipeline
guard = OutputGuardrail()
guard.add_validator(schema_validator(product_schema))
guard.add_validator(regex_content_filter)
# Run a guarded completion
result = guarded_completion(
guardrail=guard,
messages=[{
"role": "user",
"content": """Extract product info from this description as JSON:
"The Sony WH-1000XM5 wireless headphones retail for $348.
Category: electronics."
Return ONLY a JSON object with keys: name, price, category."""
}],
model="claude-sonnet-4-5",
fallback={"name": "Unknown", "price": 0, "category": "electronics"}
)
print(result)
# {"data": {"name": "Sony WH-1000XM5", "price": 348.0, "category": "electronics"}, "attempts": 1, "model": "claude-sonnet-4-5"}Observability: Tracking Guardrail Metrics
Guardrails generate valuable operational data. Track these metrics to understand your model's reliability and optimize your pipeline:
- First-pass rate — percentage of outputs that pass validation on the first attempt. Below 90% means your prompt needs work.
- Retry success rate — how often corrective retries fix the issue. Should be above 95%.
- Fallback rate — how often you hit the fallback path. Above 1% is a red flag.
- Validator breakdown — which validators fail most often. This tells you where to focus improvement efforts.
- Latency overhead — extra time added by the guardrail pipeline. Schema validation adds ~1ms. AI classification adds 200-400ms.
Feed these into your existing monitoring stack alongside your standard API metrics. The guardrail failure rate is one of the best leading indicators of production issues — it spikes before user complaints do.
Common Pitfalls to Avoid
Overly strict schemas. If your guardrail rejects valid outputs because the schema is too rigid, you'll burn tokens on unnecessary retries. Start loose, tighten based on real failure data.
Missing the code fence strip. At least 30% of JSON extraction failures come from models wrapping output in markdown code blocks. Always strip these before validation.
No fallback for critical paths. If your checkout flow depends on AI-generated pricing, you need a fallback that returns a safe default — not an error page. Design fallbacks for every guardrailed call on a user-facing path.
Skipping the fast path. Running an AI classifier on every output is expensive. Use regex patterns for the 80% of cases that are obvious, and reserve AI classification for the edge cases. Your costs will thank you — especially when you check EzAI's pricing to see how cheap Haiku calls are.
When to Use Each Guardrail Type
Not every output needs every guardrail. Match the validation depth to the risk level:
- Low risk (internal tools, dev dashboards) — Schema validation only. Cheap, fast, catches structural errors.
- Medium risk (customer-facing text, chatbot responses) — Schema + regex content filter. Catches both structure and known bad patterns.
- High risk (financial data, medical info, legal text) — Full pipeline with AI classification. Worth the extra 200ms and fraction of a cent per call.
Start with schema validation everywhere and add layers as your failure data tells you where the gaps are. Building guardrails incrementally is safer than trying to catch everything on day one.
AI output guardrails are table stakes for production AI. They turn a "the model probably returns the right thing" into a "we guarantee the output matches our contract." The overhead is negligible — a few milliseconds for schema checks, a few cents per thousand calls for AI classification — but the protection is substantial. Start with schema_validator, add regex_content_filter, and layer in AI classification where the stakes justify it. Your on-call rotation will thank you.
All code examples in this post work with EzAI API. Sign up for free credits and start building guardrails that actually protect your users.