
If you've ever shipped an AI agent that runs more than three turns, you've seen the bill. A single conversation that started at 1,200 tokens balloons to 40,000+ by turn ten because every step replays the entire history — system prompt, tool schemas, prior messages, tool outputs, the whole pile. Latency goes up, cost goes up, and the model starts losing the plot.
This post is a working playbook for keeping multi-step agents lean. No theory dump — just the patterns that actually move the needle in production: context trimming, rolling summaries, prompt caching, and knowing when to not loop at all.
The Hidden Cost of Agent Loops
An agent loop typically looks like this: send context → model picks a tool → execute tool → append result → send everything back. Each turn the input grows by roughly the size of the last assistant message plus the tool output. With a verbose tool like read_file or web_search, that's easily 2–5k tokens per turn.
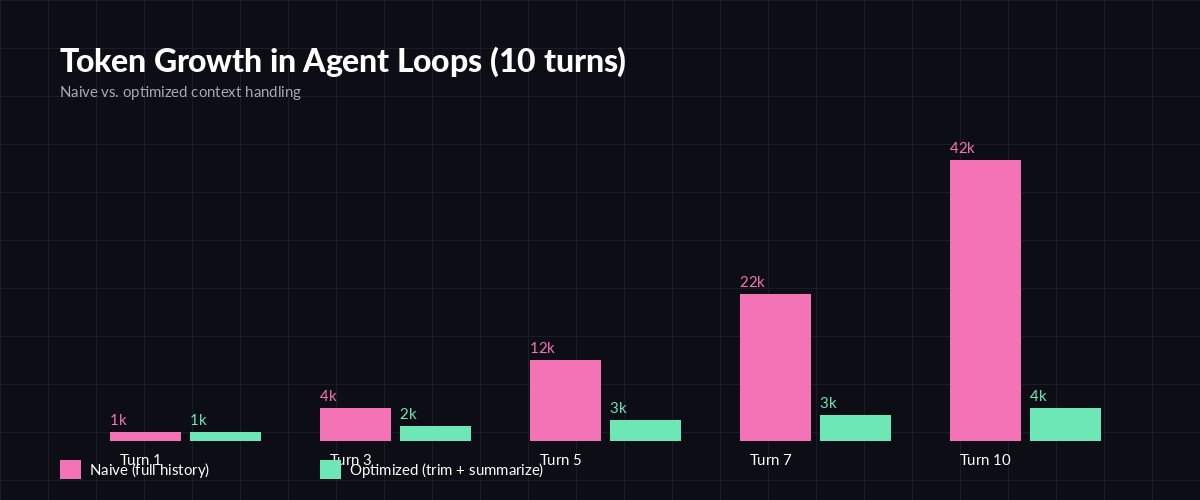
Naive history grows quadratically with turns. Optimized loops stay nearly flat.
The kicker: input tokens are billed every turn, even though most of the content hasn't changed. By turn 10 you may have sent the same system prompt ten times and the same first tool result nine times. That's pure waste.
Pattern 1 — Trim, Don't Truncate
The naive fix is "drop the oldest message when context exceeds X tokens." That breaks tool-call pairing (you'll send a tool_result with no matching tool_use) and the model returns a 400. Instead, trim in turn pairs and always preserve the original user task.
def trim_history(messages, max_tokens=12000, keep_first=1):
# messages[0] is the original user task; never drop it
head = messages[:keep_first]
tail = messages[keep_first:]
while count_tokens(head + tail) > max_tokens and len(tail) > 2:
# drop the oldest assistant + tool_result pair together
tail = tail[2:]
return head + tailRule of thumb: trigger trimming at ~70% of your context window so the next response has room. For Claude Sonnet 4.5 (200k window) that's ~140k tokens; in practice most agents should target 8–16k for cost reasons, not capacity.
Pattern 2 — Rolling Summaries
Trimming alone loses information. The fix is to summarize what you drop. Run a cheap model (Haiku, GPT-5 mini, Gemini Flash) over the dropped chunk and prepend a short "Earlier in this session:" block.
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
def summarize_chunk(dropped_messages):
text = "\n".join(str(m) for m in dropped_messages)
resp = client.messages.create(
model="claude-haiku-4-5",
max_tokens=400,
messages=[{
"role": "user",
"content": f"Summarize key facts, decisions, and tool results in <200 words:\n\n{text}",
}],
)
return resp.content[0].textA 4,000-token chunk summarized to 300 tokens is a 13× compression — and you keep the model oriented across long sessions. Don't summarize tool schemas or the active task; only summarize completed sub-steps.
Pattern 3 — Prompt Caching for Static Context
System prompts and tool schemas don't change between turns. With prompt caching, you mark them as cacheable once and pay ~10% of the input cost on subsequent turns. For agents, this is the single biggest win.
resp = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=2048,
system=[{
"type": "text",
"text": LARGE_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"},
}],
tools=tools, # tool schemas are cached automatically when system is
messages=conversation,
)Cache TTL is 5 minutes by default, which fits agent loops perfectly — most loops finish in seconds. Combined with trimming, a 30-turn agent that used to cost $0.42 can drop to $0.06 without changing the model.
Pattern 4 — Stop Loops Early
The cheapest token is the one you never send. Most agents loop too long because they don't have a clear exit condition. Add explicit termination signals:
- Max iteration cap — hard ceiling (e.g.
max_iters=15). Surface "I hit the iteration limit, here's what I have" instead of crashing. - No-progress detector — if the same tool is called with the same arguments twice, force the model to either change strategy or finalize.
- Confidence gating — ask the model to emit a
done: truefield in structured output when it believes the task is complete. Trust it; don't force one more turn "to be safe."
seen_calls = set()
for i in range(MAX_ITERS):
resp = client.messages.create(...)
if resp.stop_reason == "end_turn":
break
tool_call = extract_tool(resp)
sig = (tool_call.name, json.dumps(tool_call.input, sort_keys=True))
if sig in seen_calls:
# loop detected — inject a nudge instead of executing
conversation.append({"role": "user",
"content": "You repeated a call. Summarize and finalize."})
continue
seen_calls.add(sig)
result = run_tool(tool_call)
conversation += [resp_msg(resp), tool_result_msg(tool_call.id, result)]Putting It Together
A production agent stack looks like: cache the system prompt + tools, append turn pairs as you loop, trim when you hit ~70% of your budget, summarize what you drop, and exit on end_turn or repeat-detection. The four patterns compound — caching alone gives ~5–8× savings on input cost; trimming + summarizing gives another 3–5× on long sessions.
If you're testing this on EzAI, all four patterns work as-is — prompt caching, tool calling, and structured output use the standard Anthropic format, and you can swap models per call (Haiku for summaries, Sonnet for the main loop) without changing SDKs. Compare model behavior on the pricing page or read the related production agent architecture guide for the broader system view.
Further Reading
- Prompt caching guide — how the cache_control mechanic actually works
- Extended thinking — when reasoning tokens are worth it (and when they're not)
- Anthropic tool-use docs — official reference for the message format used above
- OpenAI function calling — equivalent patterns on the OpenAI side
Cheap agents aren't a model problem — they're a context problem. Trim, summarize, cache, and know when to stop, and you'll ship loops that scale.