
Everyone is building AI agents right now. Most of them break in production. The demo works on stage — the agent books a flight, writes code, queries a database — but deploy it to real users and you get infinite loops, hallucinated tool calls, and $400 API bills from a single runaway session.
This guide covers the architecture patterns that separate toy agents from production systems. We'll build a real agent framework in Python using Claude API through EzAI, with patterns you can steal for your own stack.
The Agent Loop: Core Architecture
Every AI agent follows the same fundamental loop: receive input, think, act, observe, repeat. The difference between a fragile demo and a production system is what happens between those steps — retry logic, token budgets, tool validation, and graceful degradation.
Here's the skeleton that every production agent needs:
import anthropic
import json, time
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com"
)
class Agent:
def __init__(self, tools, system_prompt, max_turns=15, max_tokens=100_000):
self.tools = tools
self.system = system_prompt
self.max_turns = max_turns
self.max_tokens = max_tokens
self.messages = []
self.total_tokens = 0
def run(self, user_input: str) -> str:
self.messages.append({"role": "user", "content": user_input})
for turn in range(self.max_turns):
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system=self.system,
tools=self.tools,
messages=self.messages
)
self.total_tokens += response.usage.input_tokens + response.usage.output_tokens
if self.total_tokens > self.max_tokens:
return "[Token budget exceeded — stopping agent]"
self.messages.append({"role": "assistant", "content": response.content})
if response.stop_reason == "end_turn":
return self._extract_text(response)
if response.stop_reason == "tool_use":
results = self._execute_tools(response)
self.messages.append({"role": "user", "content": results})
return "[Max turns reached — agent stopped]"Two guardrails are doing the heavy lifting: max_turns prevents infinite loops, and max_tokens caps your spend. Without these, a confused agent will happily burn through your entire balance calling the same tool in a loop.
Tool Routing: Let the Agent Do Real Work
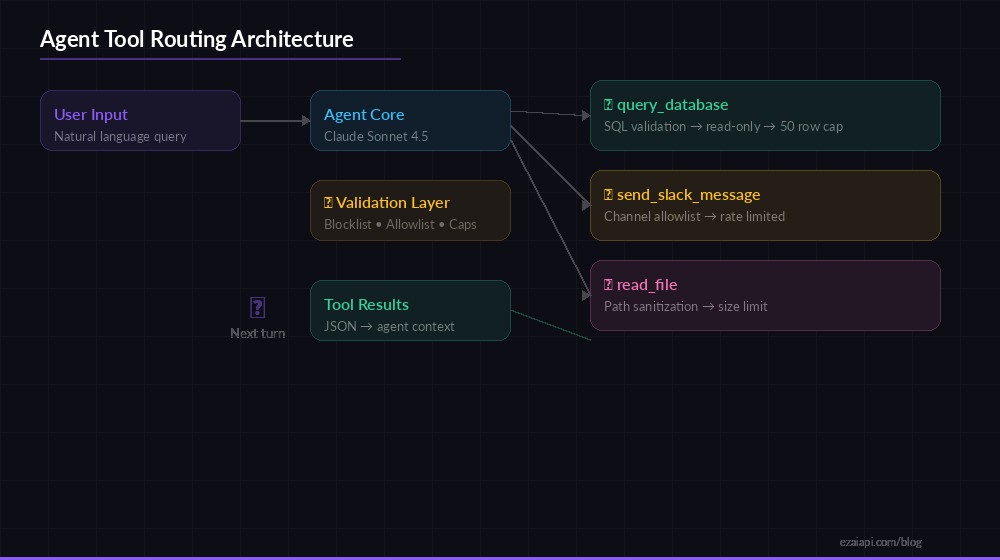
Agent tool routing — validate inputs, execute safely, return structured results
Tools are what separate a chatbot from an agent. Claude's tool use API lets you define functions the model can call, but production code needs a validation layer between the model's intent and actual execution. Never trust raw model output to hit your database.
# Define tools with strict input schemas
TOOLS = [
{
"name": "query_database",
"description": "Run a read-only SQL query against the analytics DB.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT query only"}
},
"required": ["query"]
}
},
{
"name": "send_slack_message",
"description": "Post a message to a Slack channel.",
"input_schema": {
"type": "object",
"properties": {
"channel": {"type": "string"},
"text": {"type": "string"}
},
"required": ["channel", "text"]
}
}
]
# Validation + execution layer
BLOCKED_SQL = ["DROP", "DELETE", "UPDATE", "INSERT", "ALTER", "TRUNCATE"]
def execute_tool(name: str, inputs: dict) -> str:
if name == "query_database":
query = inputs["query"].strip().upper()
if any(kw in query for kw in BLOCKED_SQL):
return json.dumps({"error": "Write operations are blocked"})
rows = db.execute_readonly(inputs["query"])
return json.dumps(rows[:50]) # Cap result size
if name == "send_slack_message":
if inputs["channel"] not in ALLOWED_CHANNELS:
return json.dumps({"error": "Channel not in allowlist"})
slack.post(inputs["channel"], inputs["text"])
return json.dumps({"ok": True})
return json.dumps({"error": f"Unknown tool: {name}"})Key patterns here: SQL queries are validated against a blocklist before touching the database, result sets are capped at 50 rows to prevent token explosion on the next turn, and Slack channels are restricted to an allowlist. The agent gets useful error messages it can reason about, not silent failures.
Memory and Context Management
Agents that run for multiple turns burn through context windows fast. A 10-turn agent conversation with tool results can easily hit 50k tokens. At $3/M input tokens for Sonnet, that's 15 cents per conversation — and it gets worse as the conversation grows because you're re-sending the entire history every turn.
The fix: summarize and compress after every N turns.
def compress_history(messages: list, keep_recent: int = 4) -> list:
"""Summarize old messages, keep recent ones intact."""
if len(messages) <= keep_recent:
return messages
old = messages[:-keep_recent]
recent = messages[-keep_recent:]
summary = client.messages.create(
model="claude-haiku-3-5", # Cheap model for summarization
max_tokens=500,
messages=[{
"role": "user",
"content": f"Summarize this agent conversation so far. "
f"Include: tools called, results obtained, decisions made.\n\n"
f"{json.dumps(old, default=str)}"
}]
)
compressed = [{
"role": "user",
"content": f"[Previous context summary: {summary.content[0].text}]"
}]
return compressed + recentThis pattern uses Haiku (at $0.25/M input tokens via EzAI) to compress older conversation turns into a summary, then keeps only the last 4 messages intact. You reduce context size by 60-80% while preserving the information the agent needs for its next decision.
Retry Logic and Error Recovery
Production agents hit errors constantly — rate limits, network timeouts, malformed tool calls, and the occasional model hallucination. Your agent loop needs to handle all of these without crashing or entering an infinite retry cycle.
import anthropic
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=30),
retry=retry_if_exception_type((
anthropic.RateLimitError,
anthropic.APIConnectionError,
anthropic.InternalServerError
))
)
def call_api(messages, tools, system):
return client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system=system,
tools=tools,
messages=messages
)
# Detect loops: same tool called 3+ times with identical args
def detect_loop(messages, window=6) -> bool:
tool_calls = []
for msg in messages[-window:]:
if msg["role"] == "assistant":
for block in msg.get("content", []):
if hasattr(block, "type") and block.type == "tool_use":
tool_calls.append(f"{block.name}:{json.dumps(block.input, sort_keys=True)}")
return len(tool_calls) >= 3 and len(set(tool_calls)) == 1The detect_loop function catches one of the most common production failures: the agent calling the same tool with the same arguments repeatedly. When detected, inject a system message telling the agent to try a different approach or report its findings. Without this, you'll see agents call query_database with an identical broken query 50 times in a row.
Multi-Model Routing for Cost Control
Per-turn cost by model — route planning to Sonnet, simple extraction to Haiku
Not every agent turn needs the same model. Planning and complex reasoning calls should use Sonnet or Opus, but simple data extraction or formatting can use Haiku at 1/12th the cost. Route by task complexity:
MODEL_TIERS = {
"planning": "claude-sonnet-4-5", # Complex reasoning
"execution": "claude-sonnet-4-5", # Tool use + decisions
"extraction": "claude-haiku-3-5", # Parse results, format output
"summarization": "claude-haiku-3-5", # Compress context
}
def pick_model(turn: int, last_stop_reason: str) -> str:
if turn == 0:
return MODEL_TIERS["planning"] # First turn: plan the approach
if last_stop_reason == "tool_use":
return MODEL_TIERS["execution"] # Mid-task: keep Sonnet
return MODEL_TIERS["extraction"] # Formatting final output: HaikuWith EzAI's unified API, switching between models is just a string change — no separate clients, no different authentication. A 10-turn agent that routes Haiku for 4 of those turns saves roughly 30-40% on total token cost compared to running Sonnet for every turn.
Observability: Logging Every Turn
When an agent does something wrong in production, you need to know exactly which turn went sideways. Log every API call with its inputs, outputs, token counts, and timing. This is non-negotiable — you can't debug agent behavior without turn-level traces.
import logging, time
logger = logging.getLogger("agent")
def traced_call(messages, tools, system, turn, session_id):
start = time.monotonic()
response = call_api(messages, tools, system)
elapsed = time.monotonic() - start
logger.info(json.dumps({
"session_id": session_id,
"turn": turn,
"model": response.model,
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
"stop_reason": response.stop_reason,
"latency_ms": round(elapsed * 1000),
"tool_calls": [
b.name for b in response.content
if hasattr(b, "type") and b.type == "tool_use"
]
}))
return responseShip these logs to whatever you already use — Datadog, Grafana, CloudWatch, even a Postgres table. The critical fields are session_id (to trace a full agent run), turn (to see where things went wrong), and tool_calls (to see what the agent tried to do). You can monitor these through EzAI's dashboard too, which shows per-request token counts and costs in real time.
Putting It All Together
Here's how these patterns combine into a production-ready agent runner:
- Token budget — Set a hard ceiling per session. Kill the loop when exceeded.
- Turn limit — Cap at 15-20 turns. Agents that need more are usually stuck.
- Tool validation — Allowlists, blocklists, and result size caps on every tool.
- Loop detection — Catch repeated identical tool calls and break the cycle.
- Context compression — Summarize old turns with a cheap model to control costs.
- Model routing — Use Sonnet for reasoning, Haiku for formatting. Save 30-40%.
- Turn-level logging — Every API call traced with tokens, timing, and tool calls.
The biggest mistake teams make is skipping the guardrails during development and bolting them on later. Build them into the core loop from day one. A runaway agent at 2 AM is an expensive and embarrassing lesson to learn from your billing dashboard.
Cost Breakdown: Real Numbers
Here's what a typical 10-turn agent session costs through EzAI with these optimizations applied:
- Turns 1-2 (planning): Sonnet, ~4k input + 2k output = ~$0.024
- Turns 3-8 (execution): Sonnet, ~8k input + 1.5k output avg = ~$0.063
- Turns 9-10 (extraction): Haiku, ~3k input + 500 output = ~$0.002
- 1x context compression: Haiku, ~6k input + 500 output = ~$0.002
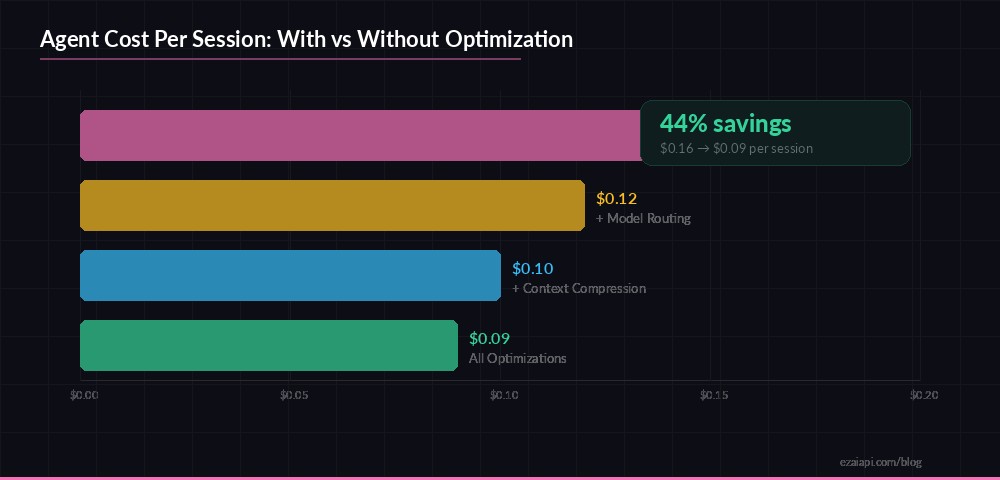
- Total: ~$0.09 per session
Without model routing and compression, the same session runs about $0.16 — nearly double. Over 10,000 sessions/month, that's a $700 difference. Not trivial.
Start building at ezaiapi.com/dashboard. All Claude, GPT, and Gemini models are available through the same endpoint, and you can switch between them with a single parameter change. Check out our guides on tool calling and multi-model fallback for more production patterns.