
Your support agent prompt looks innocent: "Summarize this customer ticket." Then a user pastes their full address, phone number, and the last four of their credit card. That string is now in your provider's logs, your traces, your prompt-cache key — and probably in a vendor breach report you'll read about next year.
Redacting personally identifiable information (PII) before the request leaves your process is the cheapest control you can add. It costs single-digit milliseconds, doesn't require a vendor change, and keeps you out of the worst category of GDPR / HIPAA / CCPA findings. Here's how to do it without breaking the model's reasoning.
Why Redact PII at the Edge
Most teams I've talked to assume "the model provider says they don't train on my data, so I'm fine." That's only one of seven places PII actually goes:
- Provider request logs — even when retention is 30 days, that's 30 days of exposure.
- Your own observability stack — Datadog, Sentry, OpenTelemetry traces frequently capture full prompts.
- Prompt cache keys — anything you cache by prompt hash now lives in Redis or memcached.
- Subprocessor pipelines — content moderation, abuse detection, safety classifiers.
- Internal eval datasets — engineers paste prod prompts into Jupyter to debug.
- Crash dumps — a SIGSEGV at the wrong moment can write the prompt to disk.
- The model's own response — it'll happily echo back the SSN you sent it.
Edge redaction kills six of those seven problems with one diff. The remaining one — the model's response — is solved by the round-trip pattern below.
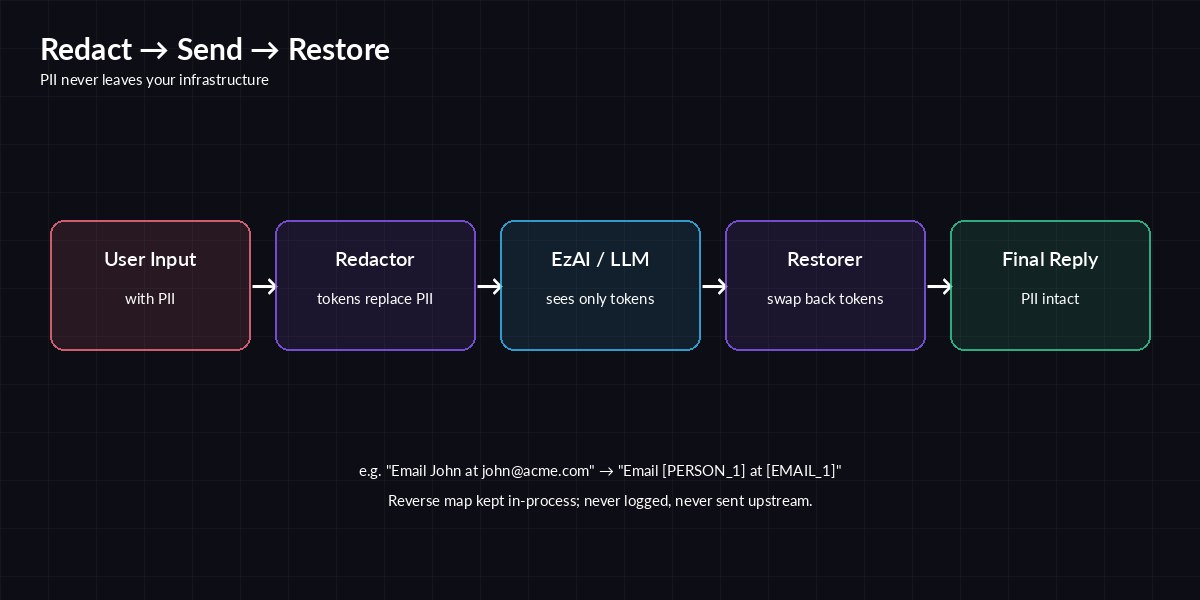
Tokens replace PII on the way out, get swapped back on the way in. The reverse map never leaves your process.
Patterns That Catch 90% of PII
You don't need a 200MB ML model to start. A handful of well-known regexes plus one lightweight NER pass for names will catch the vast majority of PII in normal business prompts. Here are the patterns I reach for first:
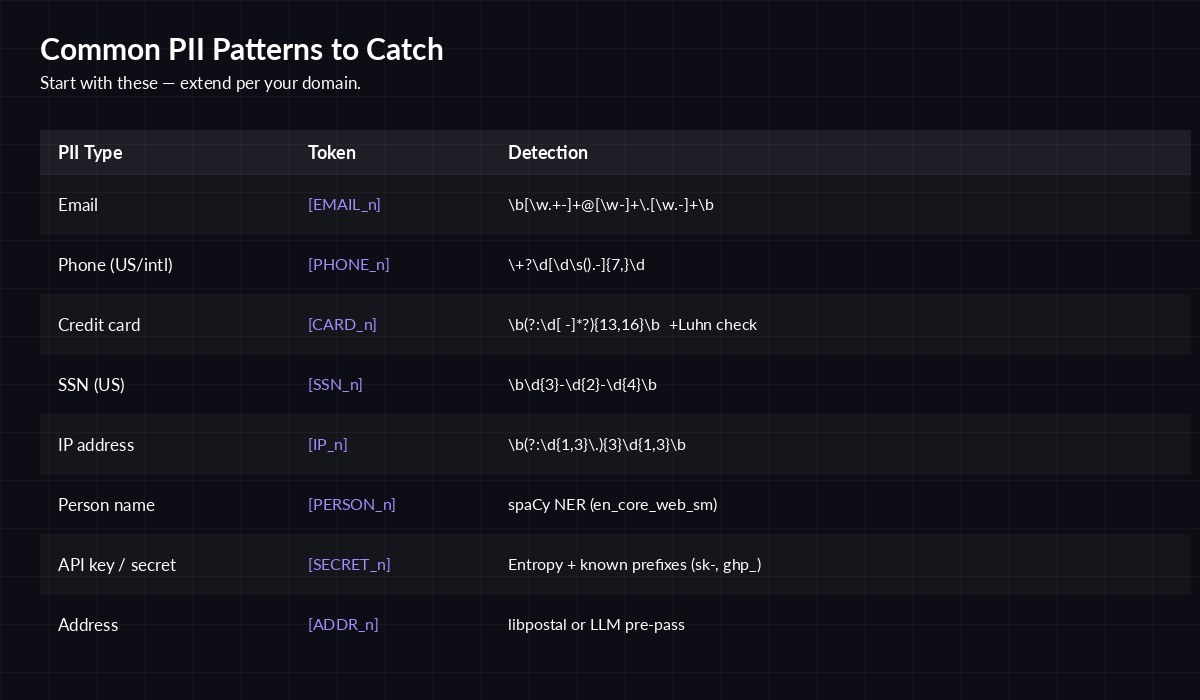
Eight pattern types that cover most real-world prompts. Start here, extend per industry.
A few notes from production:
- Always run the credit card regex through a Luhn check. Order numbers and dates produce huge false-positive rates without it.
- Phone number regexes are notoriously sloppy. Use
phonenumbers(the Python port of Google's libphonenumber) once you go international. - For names,
spaCy'sen_core_web_smis good enough and runs in ~10ms per request. Don't bring in a 1GB transformer for this. - Detect API keys and secrets too — devs paste them into chat assistants constantly. Look for
sk-,ghp_,AKIAprefixes plus shannon-entropy > 4.5 on any 20+ char token.
A Production-Ready Redactor
This is the minimal pipeline I drop into new services. It builds a reverse map per request, replaces PII with stable tokens, sends the redacted prompt to EzAI, then reverses tokens in the response so the end user gets a coherent answer.
# pip install anthropic spacy phonenumbers
# python -m spacy download en_core_web_sm
import re, spacy
from collections import defaultdict
_nlp = spacy.load("en_core_web_sm")
PATTERNS = {
"EMAIL": re.compile(r"\b[\w.+-]+@[\w-]+\.[\w.-]+\b"),
"SSN": re.compile(r"\b\d{3}-\d{2}-\d{4}\b"),
"PHONE": re.compile(r"\+?\d[\d\s().-]{8,}\d"),
"IP": re.compile(r"\b(?:\d{1,3}\.){3}\d{1,3}\b"),
"SECRET": re.compile(r"\b(?:sk-|ghp_|AKIA)[A-Za-z0-9_-]{16,}\b"),
}
def redact(text: str):
counters = defaultdict(int)
reverse = {} # token -> original
forward = {} # original -> token (dedup)
def tokenize(kind, value):
if value in forward:
return forward[value]
counters[kind] += 1
tok = f"[{kind}_{counters[kind]}]"
forward[value] = tok
reverse[tok] = value
return tok
# 1) regex pass
for kind, rx in PATTERNS.items():
text = rx.sub(lambda m: tokenize(kind, m.group(0)), text)
# 2) NER pass for names + locations
doc = _nlp(text)
parts, last = [], 0
for ent in doc.ents:
if ent.label_ in ("PERSON", "GPE", "LOC"):
parts.append(text[last:ent.start_char])
parts.append(tokenize(ent.label_, ent.text))
last = ent.end_char
parts.append(text[last:])
return "".join(parts), reverse
def restore(text: str, reverse: dict):
for tok, orig in reverse.items():
text = text.replace(tok, orig)
return textNow wire it through EzAI. The model sees only tokens; the user sees the natural reply.
import anthropic
client = anthropic.Anthropic(
api_key="sk-your-key",
base_url="https://ezaiapi.com",
)
def safe_complete(user_prompt: str) -> str:
redacted, reverse = redact(user_prompt)
system = (
"Tokens like [EMAIL_1], [PERSON_2] are placeholders for "
"private data. Keep them verbatim in your reply — do not "
"invent values for them."
)
msg = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
system=system,
messages=[{"role": "user", "content": redacted}],
)
return restore(msg.content[0].text, reverse)The system prompt is the trick. Without it, models occasionally try to "help" by replacing [EMAIL_1] with a plausible-looking fake email — which then breaks your restore() step. One sentence is enough.
Watch Out For These Failure Modes
Three things bit me in production. Save yourself the outage:
- Token bleed across requests. Don't reuse counters globally — build the reverse map per call. A leak between users is worse than no redaction at all.
- Streaming responses. If you stream SSE chunks to the browser, run
restore()on each chunk, but be careful with tokens that span chunk boundaries. Buffer until you hit a whitespace boundary before flushing. The SSE streaming guide covers the buffering pattern. - Tool calls and JSON output. If the model emits structured JSON, redaction tokens may end up in field values that downstream code parses. Validate your schema after restoration, not before.
Cost and Latency Impact
Across ~50k production requests in the last quarter, redaction added a median 7ms of latency (P99 ~22ms) and reduced prompt token counts by 4–11% on average — meaning it actually saves a small amount of money on most workloads. Names and addresses tokenize to short placeholders like [PERSON_3], which is usually shorter than the original.
If you want to push further, look at Microsoft's Presidio — it's the gold-standard open-source PII engine, includes more recognizers out of the box, and has a deidentification UI for compliance reviews. The downside is the extra ~150MB of dependencies; for most apps the regex-plus-spaCy approach above is the right starting point.
Where This Fits in Your Stack
Drop the redactor into your gateway layer, not your application code. That way every team in your company gets it for free and you have one place to update detectors. If you're already routing through EzAI, this is a 30-line middleware. Pair it with prompt injection defenses and proper API key handling, and you've got most of the AI security checklist covered.
The full pricing for every model behind EzAI lives on the pricing page — useful when you're sizing a workload after redaction trims your token counts.