
Your app throws 2,000 exceptions a day. Sentry catches them all, but your team ignores most alerts because 90% are noise — retry storms, transient timeouts, deprecated API warnings nobody cares about. The 3 real fires get buried. Sound familiar? This guide builds an AI-powered error monitor that reads raw exceptions, classifies them by severity, deduplicates the noise, and sends a clean Slack message with the root cause and a suggested fix. Total build time: about an hour. Cost per 1,000 errors classified: roughly $0.12 using Claude Haiku through EzAI API.
How the Pipeline Works
The system has four stages. Errors come in through a webhook endpoint (or log tail), get deduplicated with a rolling hash window, pass through Claude for classification, and land as a structured alert in Slack or Discord. Each stage is independent — you can swap the input source or output channel without touching the AI logic.
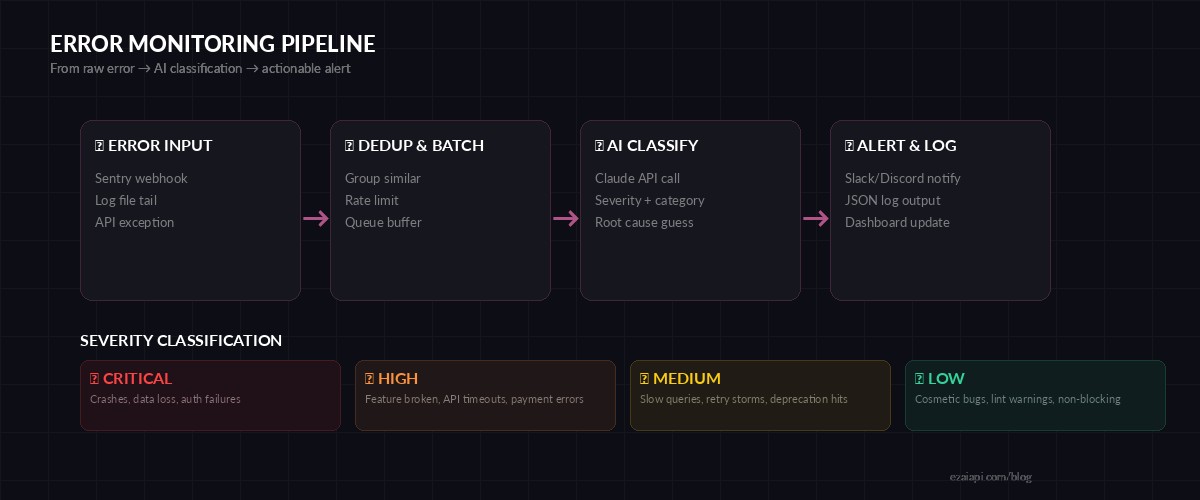
Four-stage pipeline: ingest → deduplicate → classify → alert
The core insight: Claude is remarkably good at reading stack traces. Feed it an exception with context, and it returns a severity level, a category tag, and a one-sentence root cause — all in structured JSON. That turns your error inbox from a firehose into a prioritized queue.
Project Setup
You need Python 3.10+, an EzAI API key, and pip install anthropic flask. The Flask server receives webhook payloads. Anthropic SDK handles the AI calls through EzAI's endpoint.
mkdir ai-error-monitor && cd ai-error-monitor
pip install anthropic flask requestsSet your environment variables. EzAI uses the same SDK — just point the base URL:
export ANTHROPIC_API_KEY="sk-your-ezai-key"
export ANTHROPIC_BASE_URL="https://ezaiapi.com"
export SLACK_WEBHOOK="https://hooks.slack.com/services/T.../B.../xxx"The Error Classifier
This is the core module. It takes a raw error payload — exception type, message, stack trace, and optional request context — and asks Claude to classify it. The prompt is specific: return JSON with exactly four fields, nothing else.
# classifier.py
import json, anthropic
client = anthropic.Anthropic(
base_url="https://ezaiapi.com"
)
CLASSIFY_PROMPT = """Classify this application error. Return ONLY valid JSON:
{
"severity": "critical|high|medium|low",
"category": "auth|database|network|validation|payment|internal|external_api",
"root_cause": "One sentence explaining the likely cause",
"suggested_fix": "One sentence suggesting a fix"
}
Error type: {error_type}
Message: {message}
Stack trace (last 15 lines):
{stack_trace}
Request context: {context}"""
def classify_error(error_type, message, stack_trace, context=""):
response = client.messages.create(
model="claude-haiku-3-5",
max_tokens=256,
messages=[{
"role": "user",
"content": CLASSIFY_PROMPT.format(
error_type=error_type,
message=message,
stack_trace="\n".join(stack_trace.splitlines()[-15:]),
context=context or "none"
)
}]
)
return json.loads(response.content[0].text)We use claude-haiku-3-5 because it's fast (under 400ms per call), cheap ($0.25/M input tokens through EzAI), and accurate enough for error triage. For the same cost as one Opus call, you can classify roughly 800 errors. If you need deeper analysis — say, for critical errors — you can route those to Sonnet while keeping Haiku for the rest.
Deduplication Layer
Without dedup, a single database connection pool exhaustion generates 500 identical errors in 30 seconds. Each one triggers an AI call and a Slack message. Your team mutes the channel. Game over. The fix is a rolling hash window that groups identical error signatures within a time window:
# dedup.py
import hashlib, time
from collections import defaultdict
class ErrorDeduplicator:
def __init__(self, window_seconds=300):
self.window = window_seconds
self.seen = defaultdict(lambda: {"count": 0, "first": 0})
def signature(self, error_type, message):
# Strip variable parts (IDs, timestamps) for grouping
normalized = f"{error_type}:{message[:80]}"
return hashlib.sha256(normalized.encode()).hexdigest()[:16]
def should_process(self, error_type, message):
sig = self.signature(error_type, message)
now = time.time()
entry = self.seen[sig]
# Clean expired entries
if now - entry["first"] > self.window:
self.seen[sig] = {"count": 1, "first": now}
return True, 1
entry["count"] += 1
# Only process 1st, 10th, 100th occurrence
if entry["count"] in (1, 10, 100, 1000):
return True, entry["count"]
return False, entry["count"]The logarithmic alert pattern (1st, 10th, 100th) keeps your team informed that the error is recurring without flooding the channel. The 10th-occurrence alert includes "occurred 10 times in 5 minutes" — that's a different signal than a one-off exception.
Webhook Server
The Flask app ties everything together. It accepts a POST payload with the error details, runs dedup, classifies with Claude, and fires the alert. Production deployments should add authentication (a shared secret header), but this shows the core flow:
# server.py
import os, json, requests
from flask import Flask, request, jsonify
from classifier import classify_error
from dedup import ErrorDeduplicator
app = Flask(__name__)
dedup = ErrorDeduplicator(window_seconds=300)
SEVERITY_EMOJI = {
"critical": "🔴", "high": "🟠",
"medium": "🟡", "low": "🟢"
}
def send_slack_alert(classification, error_data, occurrence_count):
emoji = SEVERITY_EMOJI.get(classification["severity"], "⚪")
count_text = f" (x{occurrence_count})" if occurrence_count > 1 else ""
blocks = [{
"type": "section",
"text": {
"type": "mrkdwn",
"text": (
f"{emoji} *{classification['severity'].upper()}*{count_text}"
f" — `{error_data['error_type']}`\n"
f"*Root cause:* {classification['root_cause']}\n"
f"*Fix:* {classification['suggested_fix']}\n"
f"*Category:* {classification['category']}"
)
}
}]
requests.post(
os.environ["SLACK_WEBHOOK"],
json={"blocks": blocks}
)
@app.post("/webhook/error")
def handle_error():
data = request.get_json()
error_type = data.get("error_type", "UnknownError")
message = data.get("message", "")
should_process, count = dedup.should_process(error_type, message)
if not should_process:
return jsonify({"status": "deduped", "count": count}), 200
classification = classify_error(
error_type=error_type,
message=message,
stack_trace=data.get("stack_trace", ""),
context=data.get("context", "")
)
send_slack_alert(classification, data, count)
return jsonify({"status": "classified", **classification}), 200
if __name__ == "__main__":
app.run(port=5050)Wiring It to Your App
You can feed errors into this system from anywhere. Here's a Python exception handler that forwards uncaught exceptions to your monitor:
# In your app — drop this in your exception middleware
import traceback, requests
def report_error(exc, request_context=None):
requests.post("http://localhost:5050/webhook/error", json={
"error_type": type(exc).__name__,
"message": str(exc),
"stack_trace": traceback.format_exc(),
"context": request_context or ""
})If you're using Sentry, you can set up a Sentry webhook that forwards events to your /webhook/error endpoint. Parse the Sentry payload to extract the exception type, message, and stack trace, and the rest of the pipeline handles classification automatically.
Cost Breakdown
Each error classification uses roughly 300 input tokens (error + prompt) and 80 output tokens (JSON response). With Claude Haiku through EzAI:
- Input: 300 tokens × $0.25/M = $0.000075
- Output: 80 tokens × $1.25/M = $0.0001
- Per error: ~$0.00018
- 1,000 errors/day: ~$0.18/day → roughly $5.40/month
That's less than one Starbucks order to triage every single error your application throws. With dedup enabled, the real API cost drops further — if 70% of your errors are duplicates, you're paying about $1.60/month. Compare that to Sentry's $26/month team plan, and you're getting AI-powered triage on top for pocket change. Check the EzAI pricing page for current rates across all models.
Taking It Further
This baseline handles the 80% case. For production hardening, consider adding:
- Persistent storage: Write classifications to SQLite or Postgres so you can query error trends over time. A weekly cron that asks Claude to summarize the week's top error patterns is surprisingly useful.
- Model routing: Use Haiku for initial triage, but escalate critical errors to Sonnet for deeper analysis. The cost difference is negligible for the 2-5% of errors that actually matter.
- Batch processing: Instead of classifying errors one at a time, batch 10-20 errors into a single Claude call. Input tokens increase, but you save on per-request overhead. See our guide on reducing AI API costs for more batching strategies.
- Auto-assign: Map error categories to team owners.
paymenterrors go to the billing team's Slack channel,autherrors go to security.
The whole system runs in about 120 lines of Python. Clone the pattern, swap in your error source, and you'll wonder why you ever stared at raw stack traces in Sentry.